 Maximilian Filtenborg
Maximilian Filtenborg
A blogpost on the modern data stack, where we look at the pros and cons of this new data architecture.
In today’s data-driven world, businesses and organizations are collecting and analyzing more data than ever before. Businesses are using more software tools to empower their organization, and are collecting more data with their applications. To create one source of truth of their data and handle the increasing amount of sources of data, a new approach to data management has emerged: the modern data stack (MDS). The modern data stack is a ‘modern’ set of tools that together compromise a new approach to building data warehouses, from ingestion to transformation and serving of the data. The modern data stack is a set of independent tools and technologies that work together to enable businesses to collect, process, store, and analyze data at scale.
In this blog post, we’ll explore what the modern data stack is, why it matters, and how it can help businesses excel at using their data. We’ll also discuss some key components of the modern data stack and take a look at the pros and cons of a modern data stack. Whether you’re a data analyst, a business owner, or simply interested in the world of data, this post will give you a better understanding of this powerful approach to building data warehouses.
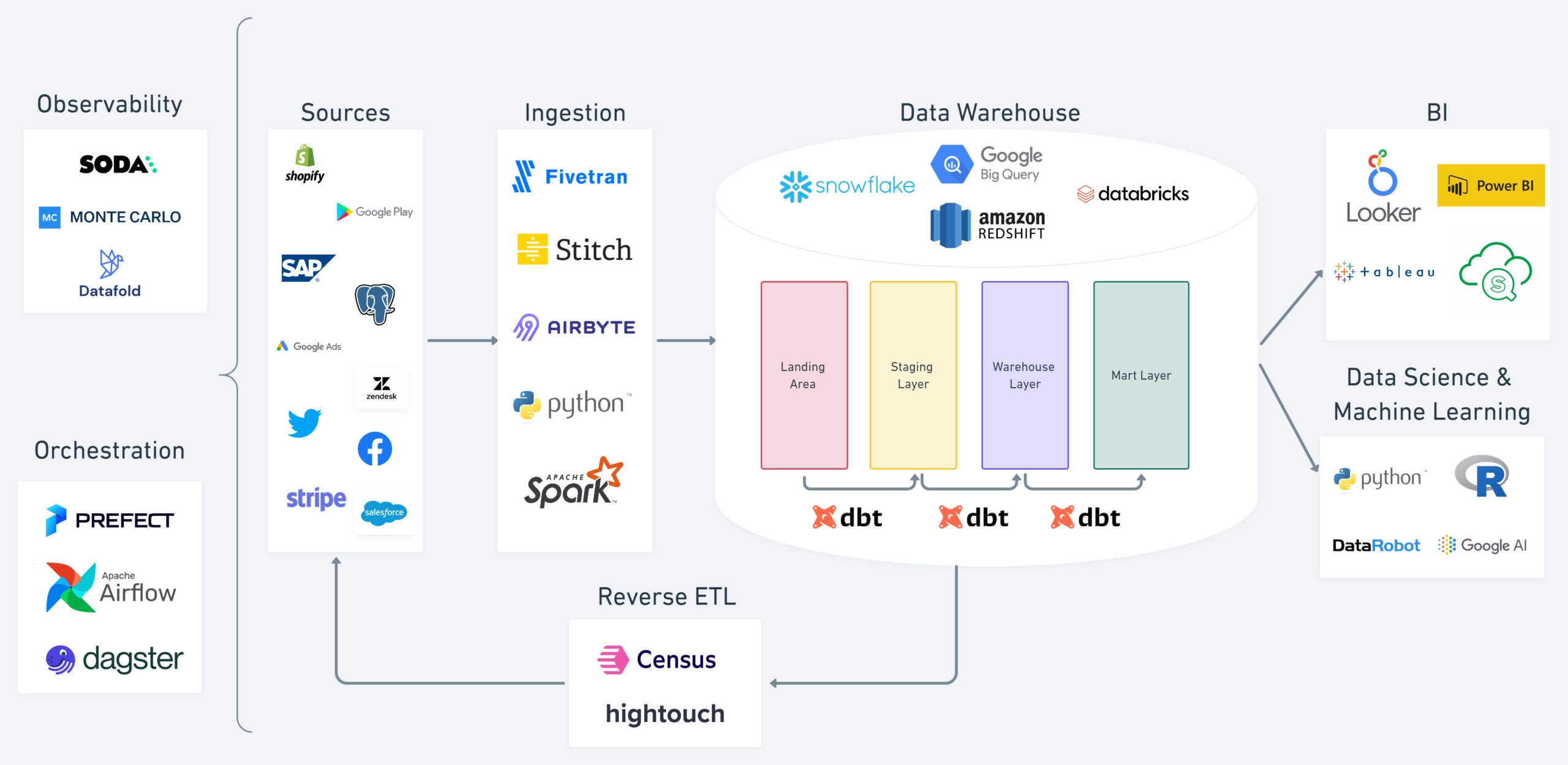
A typical modern data stack uses (some of) the following components:
Source: dbt blog on solving 4 data engineering pain points
In essence, the MDS is an approach to building data warehouses and data pipelines using cloud software and managed solutions, enabling quick iterations and a focus on business value instead of data infrastructure.
Next, we look at the aspects that together make up the Modern Data Stack.
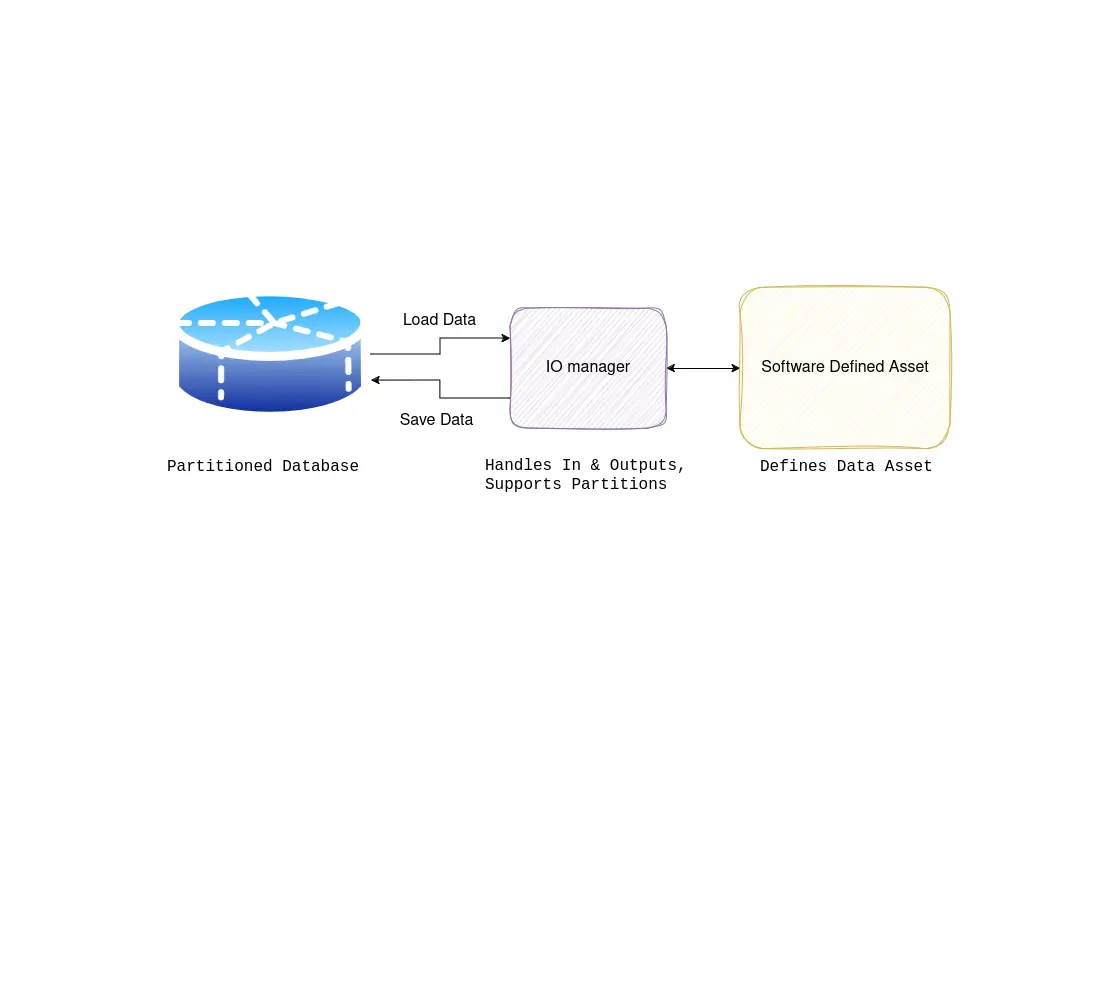
From ETL to ELT: SQL First. Classically, data pipelines were built in an extract-transform-load (ETL) fashion with handwritten data plumbing code in python or Scala (Spark) code. Conversely, a more modern way is to approach it as an ELT problem instead. This means that we load the data into the warehouse before we start transforming it, allowing us to use the power of SQL to transform our data inside the warehouse. This approach has its merits, as SQL is a very powerful language and also much more accessible compared to writing custom data transformation code. One downside of SQL is that it is hard to document it, as it is often not version controlled, and even if it is, it is hard to keep your SQL code tidy and re-usable. In addition, SQL is a declarative language, which means that it is very powerful but much harder to re-use than normal code. This is where dbt (data build tool) comes in, as it uses a version-controlled modular approach to writing SQL, allowing for code reuse and good documentation. Having said that, there is no free lunch in IT, when you want to perform more complex operations SQL is often not very well suited to perform these, meaning you will want to fall back to your favorite programming language.
Using Managed Tooling for ETL. By using managed ETL SaaS software like Fivetran, we can automate the boring stuff, and spend more time where it matters. These vendors offer products that automate (a part of) your ETL pipeline such that you don’t need to write any code yourself for the plumbing of your data. They allow you to filter and transform your data and synchronize continuously or periodically to your (cloud) data warehouse. Out of the box these tools have extensive support for connecting to numerous applications like HubSpot, Facebook, and LinkedIn and your operational databases like MySQL and PostgreSQL.
The modern data stack lets you get up and running in no time, and is built from the ground up with various tools. This means that every component of your data stack can ‘easily’ be changed, allowing you the maximum flexibility in terms of your setup. Instead of focusing your IT talent (which was already scarce) on maintaining your infrastructure, empower your users to focus on getting insights out of the data and building products on top of your data. Additionally, if you do want to build various parts of your stack from scratch, you can easily do that, but not reinvent the wheel where it is not necessary.
The MDS allows you to build on top of the software of giants instead of adopting the ‘not invented here syndrom’. Consider whether the business value from your analytics solution is coming from how well you manage your data pipelines and data infrastructure, versus how well you build analytics and AI products on top of your infrastructure.
Cloud computing has revolutionized the way businesses manage their IT infrastructure, but it can also be expensive if not managed properly, especially when deploying a modern data stack.
Choosing the right pricing model and optimizing your costs for your use case is a vital aspect when deploying to the cloud in general, but especially when deploying an MDS. Carefully consider whether you need an ‘always on’ (flat-rate: you pay for certain hardware resources) cloud data warehouse or an on-demand pricing model like big query offers (you pay per terabyte processed). Additionally, look forward and try to predict whether this will change, and how likely it is that this will change.
Snowflake for example does not support on-demand pricing, this means that you will have to pay a flat rate for your database being responsive, at the hours you need it to be. This can be acceptable if, for example, you have an embedded analytics solution that is used by thousands or more users per day, as paying for every analytics query processed gets expensive in this model. On the other hand, if you only use your data warehouse for BI, you might get away with using an on-demand model lowering your costs significantly.
Thirdly, if you are doing operational analytics, you might need a real-time data pipeline. This can get very expensive if you process a lot of data, make sure to consider the trade-offs and forecast your storage & compute needs for the foreseeable future.
Once you deploy your solution, an important aspect is cost monitoring, planning and optimization. Monitor the amount of storage and compute you use, and whether it is being used effectively, and leverage the cloud to dynamically and automatically scale down your resources if you don’t need them.
Here we list some of the most important considerations before you start building your new data stack.
Vendor lock-in. A hot topic for some time now, this is especially the case for the MDS. Most cloud data warehouse technologies that we listed, like BigQuery, Redshift and Snowflake are not open source. This means that if you start relying on the fancy features provided by these vendors, you are also locking yourself into their product. This is a double-edged sword, as one of the reasons why we want to use these technologies is also because they deliver some exceptional features.
Cloud egress costs. What happens in vegas the cloud, stays in vegas the cloud. As you pour more data into your MDS, it also gets more expensive to get your data out of it. In most clouds moving data into the cloud is free or basically free, but moving your data out of the cloud is quite expensive. For example, the egress cost in google cloud (at the time of writing) is 0.11 cents per GB (for the first 10 TB per month). This makes it quite pricey to sync data (assuming >100GB) out of the cloud (or to another region) on a daily basis. A one-time egress of 50TB would cost you around 4.000 euros, which is quite some money just to send your data over the network. This also ties into the point about vendor lock-in, as syncing data between different regions and different cloud vendors can get expensive.
Development Environment. As most of the tools listed are not open-source, we cannot simply run a docker container locally to start developing. For some tools this is quite logical, such as Fivetran, but it is still something that should be mentioned and something you need to take into account when designing your different deployment environments. To properly test your setup you will need to set up environments where your developers can test and develop data pipelines, with the ability to easily destroy them to avoid racking up cloud costs, CI/CD pipelines, IaC and tools like Terraform can help with this.
Cloud, hybrid or on-premise deployment. Adopting an MDS is appealing for many reasons, but this is not one of them. Deploying your MDS in a hybrid cloud environment will be challenging for all the reasons mentioned above, especially considering cloud egress costs and the biggest data warehouses not being open-source. On-premise deployment is possible, but many of the tools were built cloud-first, meaning you will miss out on many of the features now available in the MDS. In addition, deploying a data stack on-premise will be a huge investment, and will be very hard to do right. Teams that have the required expert knowledge in-house that see the value in processing and storing data at very high quantities, high throughput, and high loads, can consider this. Also, consider whether you really have big data, check out this related blog post from the makers of DuckDB.
Streaming analytics is becoming more and more important, as we are finding new ways to use real-time data streams to make automated decisions and run our businesses. Having said that, dbt and airflow, the tools that are often at the center of the MDS for data transformation and orchestration purposes are not streaming first solutions. A recent post link has shown that it is possible, but as of writing this doesn’t seem very well-supported yet. Consider software like Apache Beam instead, and consider one of the cloud offerings to deploy it.
In this post we have taken a look at the Modern Data Stack, a approach empowering organisations to become more data driven faster. Enjoyed reading this post? Follower our newsletter to stay up to date on the latest developments in the data engineering & science field.

Maximilian is a machine learning enthusiast, experienced software engineer, and co-founder of BiteStreams. In his free-time he listens to electronic music and is into photography.
Read moreEnjoyed reading this post? Check out our other articles.
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg