 Donny Peeters
Donny Peeters
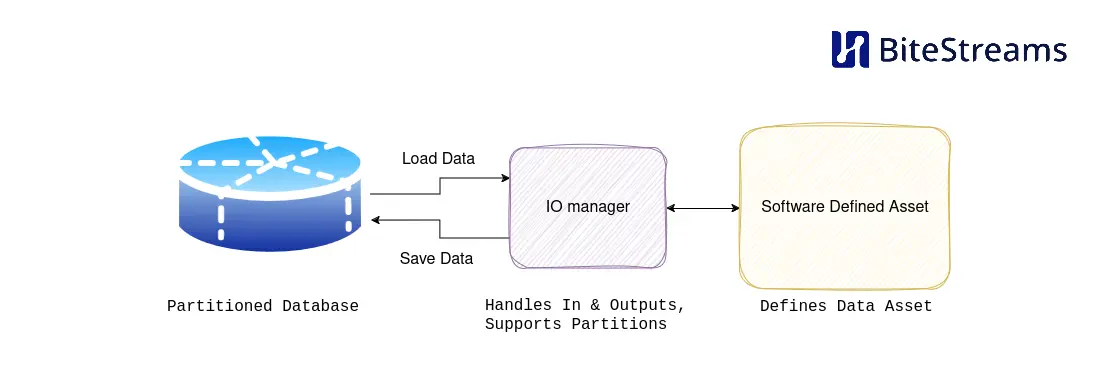
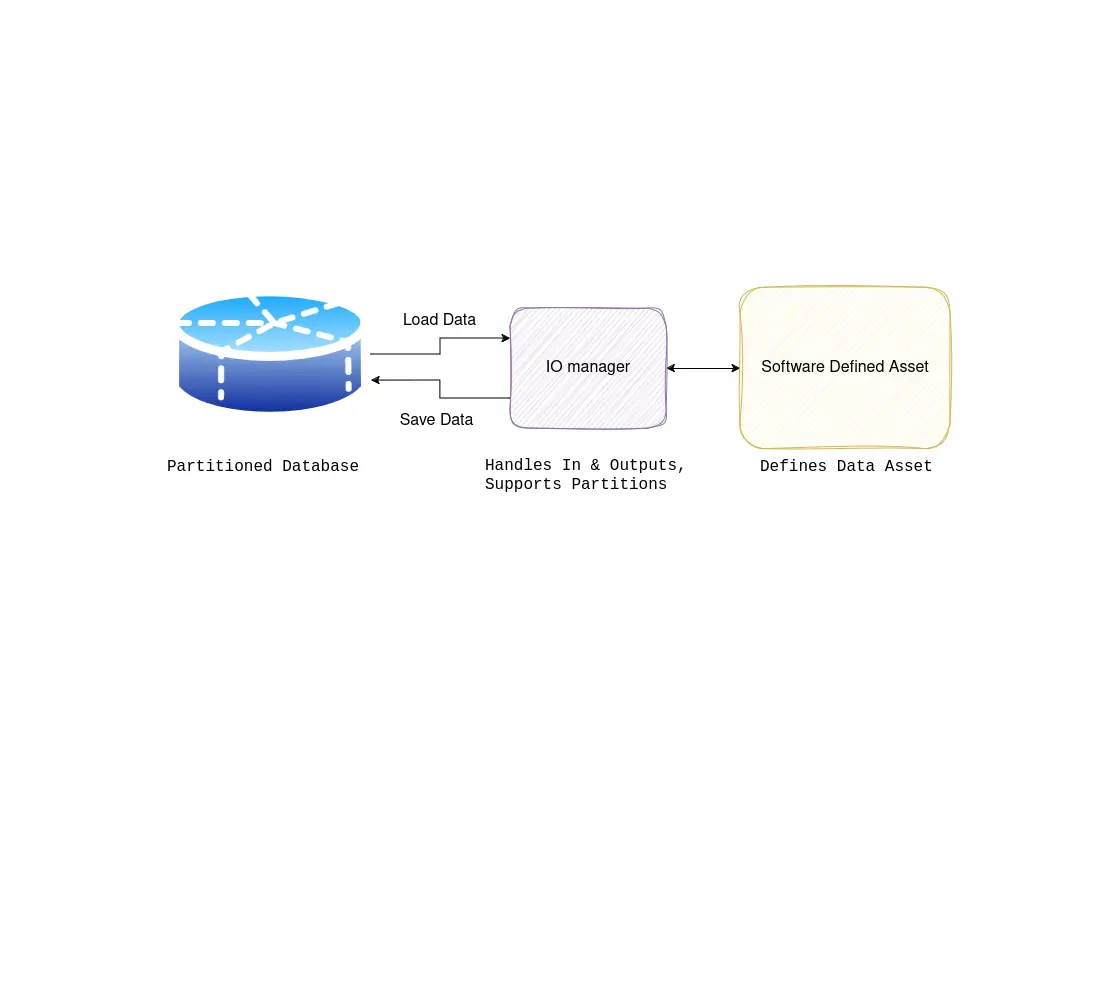
In this blog, we describe how you can build your own Dagster IO managers and use AWS Redshift as an example. We elaborate on the fundamentals on IO managers, and the tips and tricks we’ve learned building different IO managers over time.
From the IO manager documentation of Dagster:
I/O managers are user-provided objects that store asset and op outputs and load them as inputs to downstream assets and ops. They can be a powerful tool that reduces boilerplate code and easily changes where your data is stored.
IO managers, combined with partitions, are one of the most powerful concepts in Dagster; in essence, they allow you to avoid re-writing code to load and retrieve data from different sources, often your database of choice. This is immensely powerful once you realize that much of your code is just reading and writing to databases, file storage, etc. The interesting part of your code is the transformations you perform on the data; loading and retrieving data is necessary but does not add much value. Thus, when the IO manager is a great fit for our problem, we should consider using one.
When all you have is a hammer, everything looks like a nail.
Every programmer has encountered this, a good example being the RDBMS. As with any abstraction, it works great until it doesn’t. The dagster IO manager is just one tool in your toolbox, and when it doesn’t fit the problem at hand, you shouldn’t use it.
The IO manager has several assumptions that make it great for loading data into a function, doing something with it, and then storing some data. However, if this is not the abstract pattern of your problem, the IO manager might not be of much help.
For instance, if your workflow involves complex data transformations that don’t neatly fit into the input-process-output model supported by the IO manager, trying to force it into that framework could lead to convoluted and inefficient code. In such cases, it’s better to step back and evaluate whether using the IO manager aligns with the natural flow of your problem or if a different approach might be more suitable.
Ultimately, choosing the right tool for the job involves understanding the problem domain, considering the specific requirements and constraints, and being willing to adapt and explore alternative solutions when necessary. The dagster IO manager is a valuable tool in your toolbox, but it’s important to recognize when it’s the right tool for the task at hand and when another approach might be more appropriate.
Before we dive into the implementation details of an IO manager, lets first highlight some best practices and tips for developing and utilizing IO managers effectively. In this section we’ve tried to note the most important points to consider.
Implement robust error handling mechanisms within your IO manager to gracefully handle failures and recover from errors. This includes handling network issues, authentication errors, and data inconsistencies to ensure the reliability of your data pipelines.
Automate schema creation within your IO manager where possible. This streamlines data storage, reduces errors, and ensures consistency. Dynamic schema generation based on input data or templates enhances scalability and adaptability, optimizing Dagster pipeline efficiency. Also consider what happens if the schema in the database doesn’t match the schema of the data input, throwing an error in this instance can be a good idea.
Implementing idempotence using Dagster partitioning adds an extra layer of reliability to your data operations. By partitioning your data into distinct segments based on certain criteria (like time intervals or data sources), you create a structured approach to handling retries and failures. Each partition represents a self-contained unit of work, making it easier to track and manage data processing tasks. If something goes wrong during processing, you can retry individual partitions without affecting others, ensuring consistent results across your pipeline. Leveraging Dagster partitioning in conjunction with idempotent logic reinforces the integrity of your data operations, minimizing the risk of errors and inconsistencies. This is pretty much a must-have.
Optimize the performance of your IO manager by minimizing latency and maximizing throughput. This involves optimizing data transfer mechanisms, leveraging caching strategies, and parallelizing data operations where possible to improve overall pipeline efficiency. Concrete strategies are batching your operations, doing work concurrently or in parallel, and caching heavy operations.
Design your custom IO manager with reusability and modularity in mind. Consider abstracting common functionality into reusable components or libraries to facilitate easier integration across multiple pipelines and projects.
Having laid the groundwork for what an IO manager should look like, let’s now look at a real-world example of how to set up an IO manager.
In this guide, we’ll implement a custom IO manager for Redshift, Amazon Web Services’ (AWS) data warehousing solution. We will focus on storing data from Redshift clusters within Dagster pipelines. The custom IO manager we’ll develop will handle schema management, data saving, and partition management, providing a comprehensive solution for interacting with Redshift databases within Dagster workflows. The in and output types of this IO manager are pandas, one of the most used libraries. For better performance, we would recommend using other libraries like pyarrow or polars.
Our Redshift IO manager will bridge the gap between Dagster pipelines and a Redshift cluster, facilitating the movement of data between these environments. This custom IO manager will leverage AWS services such as S3, which allows us to store data as efficiently as possible.
The key functionalities of our Redshift IO manager include:
To initialize our RedshiftPandasIOManager, we have the following definition:
class RedshiftPandasIOManager(ConfigurableIOManager):
region_name: str
cluster_identifier: str
user: str
database: str
host: str
port: str
s3_iam_role: str
bucket_name: strTo set up the Redshift Pandas IO manager, provide AWS credentials, Redshift cluster details, and S3 bucket configurations. Initialize the IO manager as follows:
from dagster import Definitions
resources = {
"io_manager": RedshiftPandasIOManager(
host=EnvVar("AWS_REDSHIFT_HOST"),
database=EnvVar("AWS_REDSHIFT_DATABASE"),
port=EnvVar("AWS_REDSHIFT_PORT"),
user=EnvVar("AWS_REDSHIFT_USER"),
cluster_identifier=EnvVar("AWS_REDSHIFT_CLUSTER_IDENTIFIER"),
region_name=EnvVar("AWS_REDSHIFT_REGION_NAME"),
s3_iam_role=EnvVar("AWS_REDSHIFT_S3_IAM_ROLE"),
bucket_name=EnvVar("AWS_REDSHIFT_BUCKET_NAME"),
),
}
defs = Definitions(
assets=all_assets,
resources=resources,
# ...
)When it’s given as the io_manager in the resources dictionary of your Dagster Definitions object, it will be used for all of your assets by default.
Schema management is critical for maintaining alignment between Redshift databases and the data being processed. Our custom Redshift IO manager automates schema creation and table structure definition to streamline database interactions.
Our schema management functionality comprises:
Let’s explore the implementation within RedshiftPandasIOManager:
create_schemas Method: This method establishes a connection to Redshift and executes SQL queries to create schemas and tables. The table structure is defined based on the column types extracted from the input data.def create_schemas(self,
context: "OutputContext",
columns_with_types: dict[str, str],
full_table_name: str,
partition_key: Optional[str],
schema: str):
context.log.debug(f"creating db-schemas for {schema=} {full_table_name=} {partition_key=}")
with (
self.get_connection() as connection,
connection.cursor() as cursor
):
try:
cursor.execute(f"CREATE SCHEMA IF NOT EXISTS {schema}")
schema_string_components = map(lambda x: f"\"{x[0].upper()}\" {x[1]}", columns_with_types.items())
schema_string = ", ".join(schema_string_components)
cursor.execute(f"CREATE TABLE IF NOT EXISTS {full_table_name} ({schema_string})")
connection.commit()
except Exception as e:
connection.rollback()
raise Failure(
description=f"Failed to create table {full_table_name} in Redshift"
f"for asset_key {context.asset_key} and partition "
f"key {partition_key}",
metadata=dict(
asset_key=context.asset_key,
partition_key=partition_key,
table_name=full_table_name,
error=str(e)
),
allow_retries=False
)_get_table_structure Function: This helper function analyzes the structure of the input data and returns a dictionary mapping column names to their respective data types.def _get_table_structure(df: pd.DataFrame) -> dict[str, str]:
columns = list(df.columns)
return {column: "VARCHAR(10000)" for column in columns}Automating schema management ensures database readiness for data ingestion, making sure the input data is compatible with the database schema.
Next, we’ll delve into efficiently clearing and saving data from Pandas DataFrames into Redshift tables.
The main functionality of our custom Redshift IO manager is efficiently storing data from Pandas DataFrames into Redshift tables. This process ensures that data is ingested into Redshift with integrity and consistency, ready for analysis and further processing.
The saving of data functionality involves several key steps:
Let’s explore the implementation of the saving data functionality within our RedshiftPandasIOManager class:
handle_output Method: This method is responsible for handling the output data and initiating the process of saving it into Redshift. Inside this method:
upload_data_to_s3 method._get_table_structure function.create_schemas method.save_data method.save_data Method: This method executes SQL queries to clear existing data (if applicable) and copy the new data from Amazon S3 into the Redshift table. It handles both full table refreshes and partition updates. Here’s how the method works:def handle_output(self, context: "OutputContext", obj: pd.DataFrame) -> None:
if obj is None or len(obj) == 0:
context.log.info(
f"{self.__class__.__name__} skipping handle_output: The asset "
f"{context.asset_key} does not output any data to store (the "
f"asset may store the result during the operation.")
return
schema = "_".join(context.asset_key.path[:-1])
table_name = context.asset_key.path[-1]
full_table_name = f"{schema}.{table_name}"
partition_key = None
if context.has_asset_partitions:
try:
partition_key = context.asset_partition_key
except CheckError as e:
raise Failure(
description=f"{self.__class__.__name__} does not support partition key ranges",
metadata=dict(
asset_key=context.asset_key
),
allow_retries=False
)
partition_expr = context.metadata.get("partition_expr")
if partition_expr is None and partition_key is not None:
raise Failure(
description=f"Asset has partition key, but no partition_expr in its metadata",
metadata=dict(
asset_key=context.asset_key,
partition_key=partition_key,
),
allow_retries=False
)
context.log.info(f"Starting process to store output of asset "
f"{context.asset_key} and partition key {partition_key} in Redshift")
s3_object_name = self.upload_data_to_s3(full_table_name, obj, partition_key)
columns_with_types = _get_table_structure(obj)
context.log.info(f"Loaded {len(obj)=} for {context.asset_key} and {partition_key=} records to disk."
f" Preparing to load these into redshift.")
self.create_schemas(context, columns_with_types, full_table_name, partition_key, schema)
self.save_data(context, s3_object_name, full_table_name, partition_expr, partition_key)
def save_data(self,
context: "OutputContext",
s3_object_name: str,
full_table_name: str,
partition_expr: str,
partition_key: Optional[str]):
context.log.debug(f"saving data for {full_table_name=} {partition_key=}")
with (
self.get_connection() as connection,
connection.cursor() as cursor
):
try:
# First clear the partition or table out.
if partition_key is None:
# Do a full refresh, and delete all data
context.log.debug(f"Fully clearing table {full_table_name} since no partition key is given")
query = f"DELETE FROM {full_table_name}"
cursor.execute(query)
else:
# Try to remove the old partition data and load the new data
context.log.debug(f"Clearing partition such that {partition_expr} = {partition_key}"
f" for table {full_table_name}")
query = f"DELETE FROM {full_table_name} WHERE {partition_expr} = %s"
cursor.execute(query, (partition_key,))
# Copy all the file starting with `s3_url_prefix` to the table `table_name`.
# The role `self.s3_iam_role is used by Redshift to authenticate to S3
# The parameter EMPTYASNULL ensures that empty strings in the csv are stored as NULL in Redshift
s3_url_prefix = f"s3://{self.bucket_name}/{s3_object_name}"
query = f"COPY {full_table_name} FROM '{s3_url_prefix}' IAM_ROLE '{self.s3_iam_role}' CSV gzip EMPTYASNULL"
cursor.execute(query)
connection.commit()
except Exception as e:
# Abort execution of the operation
connection.rollback()
raise Failure(
description=f"Failed to store data in Redshift for asset_key {context.asset_key} "
f"and partition key {partition_key}",
metadata=dict(
asset_key=context.asset_key,
partition_key=partition_key,
table_name=full_table_name,
error=str(e)
),
allow_retries=False
)In this method, we handle removing existing data before loading new data. This ensures the Redshift table is updated with the latest information, maintaining data integrity.
upload_data_to_s3 Method: This method uploads the output data in CSV (gzipped) format to Amazon S3, preparing it for loading into Redshift. def upload_data_to_s3(self, full_table_name, obj, partition_key):
buf = BytesIO()
obj.to_csv(buf, index=False, header=False, compression='gzip')
s3_object_name = f"{full_table_name}/{partition_key}.csv.gzip"
client = boto3.client("s3")
client.put_object(
Body=buf,
Bucket=self.bucket_name,
Key=s3_object_name,
)
return s3_object_nameBy implementing efficient data-saving mechanisms, our Redshift IO manager ensures that data is seamlessly integrated into Redshift for analysis and processing within Dagster pipelines.
To keep the scope of this blog somewhat simple, we have not included all the bells and whistles you might want to have. Potential improvements to the IO manager could be the following:
COPY command, splitting these files up into circa 100mb size speeds up loading of the data and prevents Redshift giving an error.The full code for the IO manager can be found here: Dagster Redshift IO manager
In this blog, we’ve explored the fundamentals of Dagster IO managers and delved into the process of building a custom IO manager for AWS Redshift. Through an in-depth analysis of each step, from schema management to data saving, we’ve provided insights into best practices and tips for developing robust and efficient IO managers.
Looking ahead, there are numerous opportunities for further enhancements and optimizations to our Redshift IO manager, such as supporting key ranges, optimizing data formats and loading strategies, and improving performance and scalability.
In conclusion, Dagster IO managers are a powerful tool for simplifying data pipeline development and management, offering flexibility, modularity, and reliability. By understanding the core principles and best practices outlined in this blog, data engineers have a robust foundation to develop their own IO managers.

Maximilian is a machine learning enthusiast, experienced data engineer, and co-founder of BiteStreams. In his free-time he listens to electronic music and is into photography.
Read moreEnjoyed reading this post? Check out our other articles.
Donny Peeters
 Maximilian Filtenborg
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg
Feel free to contact us, we don't bite.
Contact us