 Maximilian Filtenborg
Maximilian Filtenborg
Een blogpost over de moderne data stack, waar we kijken naar de voor- en nadelen van deze nieuwe data-architectuur.
In de huidige door data gedreven wereld verzamelen en analyseren bedrijven en organisaties meer gegevens dan ooit tevoren. Bedrijven maken gebruik van meer softwaretools om hun organisatie te versterken en verzamelen meer gegevens met hun toepassingen. Om één waarheidsgetrouwe bron van hun gegevens te creëren en de toenemende hoeveelheid gegevensbronnen aan te pakken, is er een nieuwe benadering van gegevensbeheer ontstaan: de moderne data stack (MDS). De moderne data stack is een ‘moderne’ set tools die samen een nieuwe benadering vormen voor het bouwen van gegevenswarehouses, van de invoer tot de transformatie en bediening van de gegevens. De moderne data stack is een set onafhankelijke tools en technologieën die samenwerken om bedrijven in staat te stellen gegevens op grote schaal te verzamelen, verwerken, opslaan en analyseren.
In deze blogpost zullen we verkennen wat de moderne data stack is, waarom het belangrijk is en hoe het bedrijven kan helpen uitblinken in het gebruik van hun gegevens. We zullen ook enkele belangrijke componenten van de moderne data stack bespreken en de voor- en nadelen van een moderne data stack bekijken. Of je nu een data-analist bent, een bedrijfseigenaar of gewoon geïnteresseerd bent in de wereld van data, deze post geeft je een beter begrip van deze krachtige benadering van het bouwen van gegevenswarehouses.
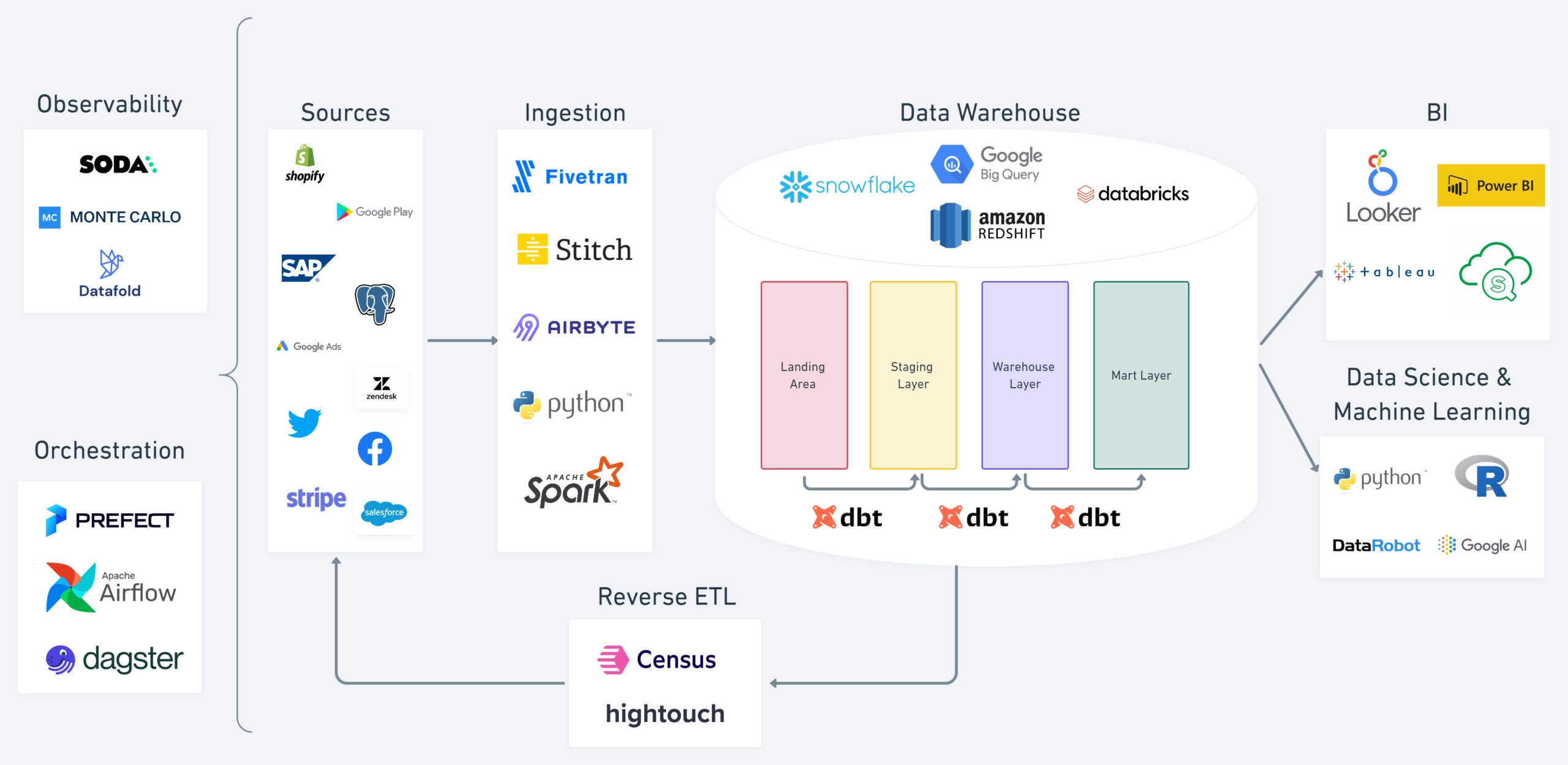
Een typische moderne data stack maakt gebruik van (een deel van) de volgende componenten:
Bron: dbt-blog over het oplossen van 4 veelvoorkomende pijnpunten in gegevensengineering
In essentie is de MDS een benadering voor het bouwen van gegevenswarehouses en gegevenspijplijnen met behulp van cloudsoftware en beheerde oplossingen, waardoor snelle iteraties en een focus op bedrijfswaarde mogelijk zijn in plaats van op data-infrastructuur.
Vervolgens bekijken we de aspecten die samen de Moderne Data Stack vormen.
Van ETL naar ELT: SQL Eerst. Klassiek werden gegevenspijplijnen gebouwd volgens het extract-transform-load (ETL)-model met handgeschreven dataplumbingcode in Python of Scala (Spark) code. Daarentegen is een meer moderne benadering om het als een ELT-probleem te benaderen. Dit betekent dat we de gegevens in het warehouse laden voordat we het gaan transformeren, waardoor we de kracht van SQL kunnen gebruiken om onze gegevens binnen het warehouse te transformeren. Deze aanpak heeft zijn verdiensten, aangezien SQL een zeer krachtige taal is en ook veel toegankelijker in vergelijking met het schrijven van aangepaste datatransformatiecode. Een nadeel van SQL is echter dat het moeilijk te documenteren is, omdat het vaak niet versiegecontroleerd is, en zelfs als dat wel het geval is, is het moeilijk om je SQL-code netjes en herbruikbaar te houden. Bovendien is SQL een declaratieve taal, wat betekent dat het zeer krachtig is maar veel moeilijker te hergebruiken dan normale code. Hier komt dbt (data build tool) in beeld, omdat het een versiegecontroleerde modulaire benadering van SQL gebruikt, wat zorgt voor hergebruik van code en goede documentatie. Dat gezegd hebbende, er bestaat niet zoiets als een gratis lunch in IT; wanneer je meer complexe bewerkingen wilt uitvoeren, is SQL vaak niet erg geschikt om deze uit te voeren, wat betekent dat je wilt terugvallen op je favoriete programmeertaal.
Gebruik van Beheerde Tools voor ETL. Door beheerde ETL SaaS-software zoals Fivetran te gebruiken, kunnen we het saaie werk automatiseren en meer tijd besteden waar het telt. Deze leveranciers bieden producten die (een deel van) je ETL-pijplijn automatiseren, zodat je geen code hoeft te schrijven voor de plumbing van je gegevens. Ze stellen je in staat om je gegevens te filteren en te transformeren en deze continu of periodiek te synchroniseren met je (cloud) gegevenswarehouse. Out-of-the-box hebben deze tools uitgebreide ondersteuning voor het verbinden met tal van toepassingen zoals HubSpot, Facebook en LinkedIn en je operationele databases zoals MySQL en PostgreSQL.
De moderne data stack stelt je in staat om in no-time operationeel te zijn en is vanaf de basis opgebouwd met verschillende tools. Dit betekent dat elk onderdeel van je data stack ‘gemakkelijk’ kan worden gewijzigd, waardoor je maximale flexibiliteit hebt wat betreft je opstelling. In plaats van je IT-talent (dat al schaars was) te richten op het onderhouden van je infrastructuur, geef je je gebruikers de mogelijkheid om zich te concentreren op inzichten uit de gegevens en het bouwen van producten bovenop je gegevens. Bovendien, als je verschillende delen van je stack vanaf nul wilt opbouwen, kun je dat eenvoudig doen, maar niet het wiel opnieuw uitvinden waar dat niet nodig is.
De MDS stelt je in staat om te bouwen op de software van giganten in plaats van het ‘not invented here syndroom’ aan te nemen. Overweeg of de bedrijfswaarde van je analytische oplossing afkomstig is van hoe goed je je gegevenspijplijnen en gegevensinfrastructuur beheert, in tegenstelling tot hoe goed je analyses en AI-producten bovenop je infrastructuur bouwt.
Cloud computing heeft de manier waarop bedrijven hun IT-infrastructuur beheren gerevolutioneerd, maar het kan ook duur zijn als het niet goed wordt beheerd, vooral bij de implementatie van een moderne data stack.
Het kiezen van het juiste prijsmodel en het optimaliseren van de kosten voor jouw gebruikssituatie zijn vitale aspecten bij het implementeren in de cloud in het algemeen, maar vooral bij het implementeren van een MDS. Overweeg zorgvuldig of je een ‘altijd aan’ (vast tarief: je betaalt voor bepaalde hardwarebronnen) cloud data warehouse nodig hebt of een model met on-demand prijsstelling zoals BigQuery biedt (je betaalt per terabyte verwerkte gegevens). Kijk ook vooruit en probeer te voorspellen of dit zal veranderen, en hoe waarschijnlijk het is dat dit zal veranderen.
Snowflake ondersteunt bijvoorbeeld geen on-demand prijzen, wat betekent dat je een vast tarief moet betalen voor je database die responsief is op de uren die je nodig hebt. Dit kan acceptabel zijn als je bijvoorbeeld een ingebedde analytische oplossing hebt die dagelijks door duizenden of meer gebruikers wordt gebruikt, omdat betalen voor elke verwerkte analytische query duur wordt in dit model. Aan de andere kant, als je je datawarehouse alleen voor BI gebruikt, kom je misschien weg met een on-demand model, wat je kosten aanzienlijk kan verlagen.
Ten derde, als je operationele analyses uitvoert, heb je mogelijk een realtime data-pijplijn nodig. Dit kan erg duur worden als je veel gegevens verwerkt. Zorg ervoor dat je de afwegingen in overweging neemt en je opslag- en rekeneisen voor de nabije toekomst voorspelt.
Zodra je je oplossing implementeert, is een belangrijk aspect het monitoren, plannen en optimaliseren van kosten. Volg de hoeveelheid opslag en rekencapaciteit die je gebruikt, en of deze effectief wordt gebruikt, en maak gebruik van de cloud om je resources dynamisch en automatisch te schalen als je ze niet nodig hebt.
Hier vermelden we enkele van de belangrijkste overwegingen voordat je begint met het bouwen van je nieuwe data stack.
Vendor lock-in. Een veelbesproken onderwerp sinds enige tijd, vooral bij de MDS. De meeste cloud data warehouse-technologieën die we hebben vermeld, zoals BigQuery, Redshift en Snowflake, zijn niet open source. Dit betekent dat als je gaat vertrouwen op de geavanceerde functies die deze leveranciers bieden, je jezelf ook vastlegt aan hun product. Dit is een tweesnijdend zwaard, omdat een van de redenen waarom we deze technologieën willen gebruiken, ook is omdat ze enkele uitzonderlijke functies leveren.
Cloud egress-kosten. Wat er gebeurt in de cloud, blijft in de cloud. Naarmate je meer gegevens in je MDS giet, wordt het ook duurder om je gegevens eruit te halen. In de meeste clouds is het verplaatsen van gegevens naar de cloud gratis of bijna gratis, maar het verplaatsen van je gegevens uit de cloud is behoorlijk duur. Bijvoorbeeld, de egress-kosten in Google Cloud (op het moment van schrijven) zijn 0,11 cent per GB (voor de eerste 10 TB per maand). Dit maakt het behoorlijk prijzig om dagelijks gegevens (onder de aanname van >100 GB) uit de cloud te synchroniseren (of naar een andere regio). Een eenmalige egress van 50TB zou je ongeveer 4.000 euro kosten, wat behoorlijk wat geld is om gewoon je gegevens over het netwerk te sturen. Dit hangt ook samen met het punt over vendor lock-in, omdat het synchroniseren van gegevens tussen verschillende regio’s en verschillende cloudleveranciers duur kan worden.
Ontwikkelingsomgeving. Omdat de meeste vermelde tools niet open source zijn, kunnen we niet eenvoudig een docker-container lokaal uitvoeren om te beginnen met ontwikkelen. Voor sommige tools is dit heel logisch, zoals Fivetran, maar het is nog steeds iets dat moet worden vermeld en iets waarmee je rekening moet houden bij het ontwerpen van je verschillende implementatieomgevingen. Om je setup goed te testen, moet je omgevingen opzetten waar je ontwikkelaars data-pipelines kunnen testen en ontwikkelen, met de mogelijkheid om ze eenvoudig te vernietigen om te voorkomen dat je cloudkosten maakt. CI/CD-pipelines, IaC en tools zoals Terraform kunnen hierbij helpen.
Cloud-, hybride- of on-premise-implementatie. Het aannemen van een MDS is om veel redenen aantrekkelijk, maar dit is er niet een van. Je MDS implementeren in een hybride cloudomgeving zal uitdagend zijn om alle hierboven genoemde redenen, vooral gezien de cloud egress-kosten en het feit dat de grootste datawarehouses niet open source zijn. On-premise implementatie is mogelijk, maar veel tools zijn cloud-first gebouwd, wat betekent dat je veel van de functies zult missen die nu beschikbaar zijn in de MDS. Bovendien zal het implementeren van een data stack on-premise een grote investering zijn en zeer moeilijk correct uit te voeren. Teams die de vereiste expertkennis in huis hebben en de waarde zien in het verwerken en opslaan van gegevens in zeer grote hoeveelheden, met een hoge doorvoer en hoge belastingen, kunnen dit overwegen. Overweeg ook of je echt big data hebt, bekijk deze gerelateerde blogpost van de makers van DuckDB.
Streaming analytics wordt steeds belangrijker, omdat we nieuwe manieren vinden om realtime gegevensstromen te gebruiken om geautomatiseerde beslissingen te nemen en onze bedrijven te runnen. Desondanks zijn dbt en Airflow, de tools die vaak in het middelpunt van de MDS staan voor gegevenstransformatie- en orchestratiedoeleinden, geen streaming-first oplossingen. Een recente post link heeft aangetoond dat het mogelijk is, maar op het moment van schrijven lijkt dit nog niet erg goed ondersteund te worden. Overweeg in plaats daarvan software zoals Apache Beam en bekijk een van de cloudaanbiedingen om het te implementeren.
In deze post hebben we gekeken naar de Modern Data Stack, een benadering waarmee organisaties sneller meer op gegevens gebaseerd kunnen worden. Genoten van het lezen van deze post? Volg onze nieuwsbrief om op de hoogte te blijven van de nieuwste ontwikkelingen op het gebied van data-engineering en data-science.

Maximilian is een liefhebber van machine learning, ervaren software-engineer en mede-oprichter van BiteStreams. In zijn vrije tijd luistert hij naar elektronische muziek en houdt hij zich bezig met fotografie en hiken.
Meer lezenEnjoyed reading this post? Check out our other articles.
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg
 Donny Peeters
Donny Peeters
Wordt meer datagedreven met BiteStreams en laat de concurrentie achter je.
Contacteer ons