 Maximilian Filtenborg
Maximilian Filtenborg
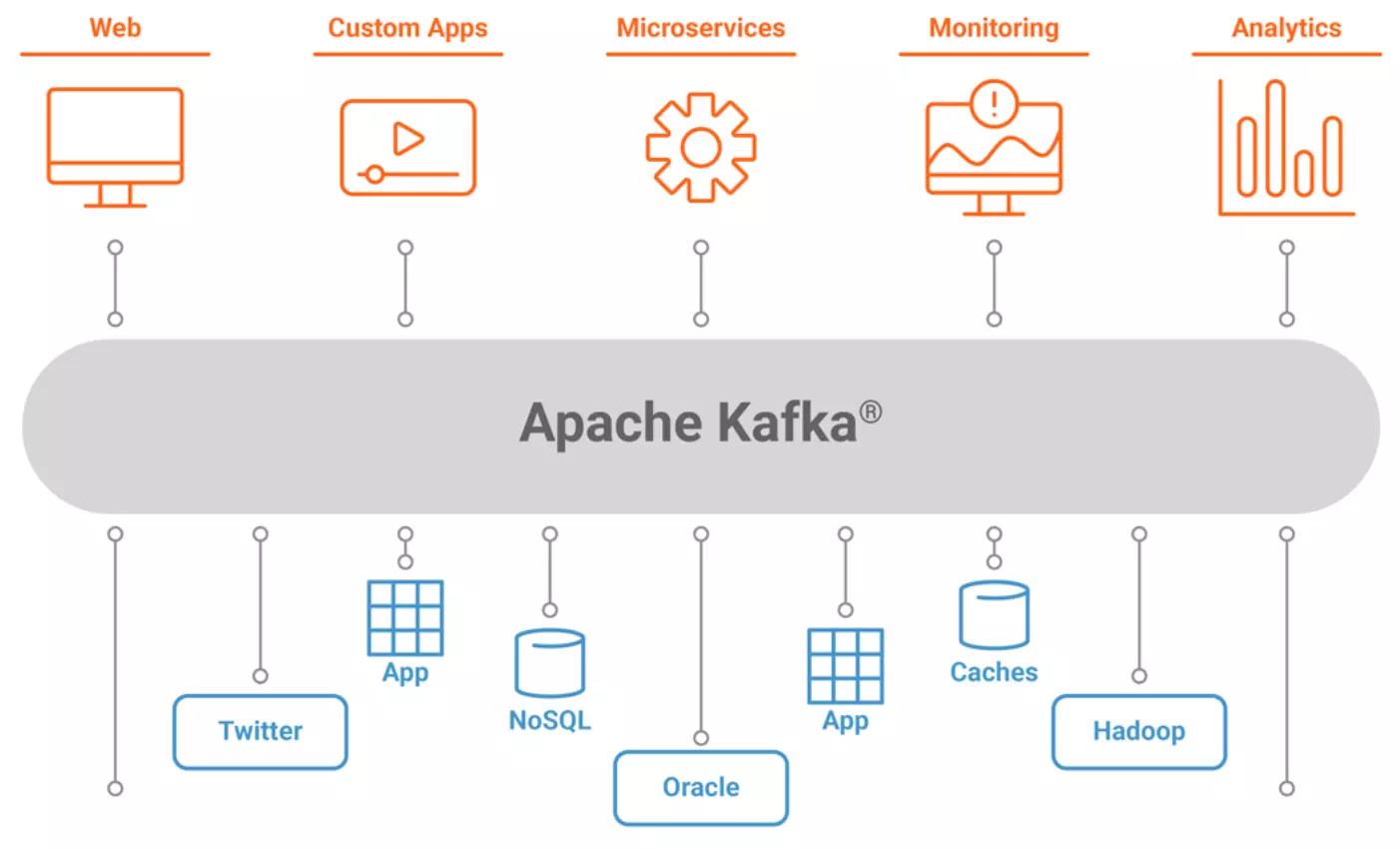
Get to know more about Apache Kafka in this writeup of Kafka's biggest advantages and misconceptions.
Apache Kafka is a technology with a fair bit of hype. In this post, we take a look at Apache Kafka and try to give insight into what Kafka is and perhaps more importantly, what it is not.
Apache Kafka is an open-source distributed streaming platform that is designed to handle real-time data feeds in a scalable and fault-tolerant manner. It has become increasingly popular in recent years, especially in the context of big data and real-time data processing.
Invented at LinkedIn, Kafka is a technology that has emerged from companies pushing the limits of data processing. The main aspect of Kafka which is quite revolutionary is the amount of data it can handle in a real-time fashion. In a way, it is an invention that is a logical advancement after the invention of Hadoop. Hadoop was a technology invented to analyze gigantic datasets but in a very slow fashion. In comparison, Kafka enables us to handle similar amounts of data as a Hadoop map-reduce job can, but then in real-time. This analogy only takes us so far, however, as Kafka is not a processing engine in and of itself.
In a nutshell, Kafka is a software tool to couple systems together, whether you are building a data warehouse or an event-driven microservices architecture, Kafka is a data streaming platform to consider. Let’s explore some of the advantages of using Kafka as a data communication platform:
Decoupled communication. Because Kafka uses a producer-consumer model for publishing data, the connection between any two systems becomes decoupled and more robust in crucial ways. Since both applications are only communicating via the Kafka protocol, neither of the two need to understand how to speak the other’s language. In more concrete terms, this means that we don’t need to integrate systems directly, and only need the producer side to publish the relevant data to a Kafka topic. The consumer of the data stream can then decide to consume this data on its own terms. One downside of this is that a request-response model of communication becomes more complicated, as there is no direct way of sending a response to a message published on a topic. Of course, there are ways to implement this as well with Kafka topics.
Robust and fault-tolerant communication. Secondly, since data communication is now done via a broker - the Kafka streaming platform, we now have a very robust and fault-tolerant communication line, which requires very little consideration from either application. Because the producer is not directly coupled to the consumer, the producer or the consumer can go offline for maintenance at any time. What will happen is that the messages between the applications will simply have a small delay before being processed by the consumer side. This is much harder to ensure when performing communication via REST endpoints. A typical bug is not implementing any fall back in a situation in which the consumer side is temporarily offline, causing messages to not be received.
Seamless integration with many systems. Thirdly, because messages are now published in Kafka, and not sent directly between applications, any application can decide to consume the stream of messages coming from an application. This enables building new integrations seamlessly as long as the relevant and required data is published. This becomes especially relevant in larger organizations dealing with many (micro-)services.
High throughput. Kafka is designed to handle large volumes of data in real-time, with high throughput and low latency. This makes it an ideal platform for processing large data streams, such as those generated by IoT devices or social media platforms.
Scalability. Kafka is a distributed platform and was designed to be scalable from the ground up. This means that it can be easily scaled out as data volumes increase. This allows even the largest organizations out there to scale their Kafka deployment as their data processing requirements increase.
Fault-tolerant. Kafka is designed to be fault-tolerant, with built-in mechanisms for replicating data across multiple nodes in the cluster. This ensures that data is always available, even in the event of hardware failures or network outages.
The architecture of Kafka brings a lot of advantages, however, there is also quite some confusion out there on what Kafka is or is not or what it can or cannot do. Below are 3 misconceptions that we have commonly seen.
Misconception #1: Kafka is a messaging system. One of the most common misconceptions about Kafka is that it is a messaging system, like RabbitMQ or ActiveMQ. While Kafka can be used for messaging, it is fundamentally a distributed streaming platform that is designed to handle real-time data feeds. Kafka stores data in topics, which can be thought of as streams of data that can be processed in real-time. This means it does not offer the same flexibility as for example RabbitMQ.
Misconception #2: Kafka is a database. Another common misconception about Kafka is that it can replace databases or data warehouses. Querying Kafka is very limited, data streams (topics in Kafka nomenclature) are consumed from beginning to end by consumers, if you need to retrieve a specific message one often needs to resort to scanning the whole stream from the beginning to the end or start at a specific timestamp in the stream.
While Kafka can be used for data storage, it is not designed to be a primary data store. Instead, one of the best use cases of Kafka is to use it as a real-time data pipeline that can feed data into databases or data warehouses for storage and analysis.
Misconception #3: Data within Kafka is ephemeral. Some of the interesting use cases of Kafka are enabled by the usage of topics that retain data forever. While messages in Kafka by default do have a TTL configured, this can also be disabled and configured server-wide or per topic. Kafka is designed in such a way that a very large topic has no downsides to up-to-date consumers, meaning that this will not slow down the Kafka cluster. This enables the implementation of certain patterns, for example, storing historical updates from an application within Kafka, for use by other consumers at a later point in time.
Apache Kafka is a tool that is very good at what it does, however, before deciding to use Apache Kafka one should fully understand what you are getting into. One of the downsides of Kafka is that it can be a complex tool. To reap the rewards of using Kafka one has to tune and configure their Kafka instance to their needs. Below we outline important details when deciding to employ Kafka for your business needs.
Pitfall #1: Not understanding partitions. The number of partitions in a Kafka topic has a big impact on its performance and scalability. The number of partitions dictates the number of consumers you can have from one topic (stream of data) at a time, this means that it bounds the maximum number of parallel processes you can have. Just as important is the fact that messages are only ordered within one partition, this is a big factor that allows Kafka to scale so well. If ordering is important for your messages (which is often the case), the application that connects to your Kafka topic needs to carefully consider this aspect.
Similarly, since the number of partitions dictates the number of parallel consumers, it is an important setting to configure well. It is not as easy as setting the number of partitions to a very high number, as having too many partitions also has its downsides in terms of complexity and extra overhead. It’s important to find the right balance based on your specific use case and workload.
Pitfall #2: Deploying a single node Kafka instance. If anything is an antipattern, this is probably it. Deploying a single-node Kafka instance means that you lose most of its key strengths, like high availability, scalability, and fault tolerance. In addition, Kafka’s fault tolerance is only really guaranteed with a well-thought-out deployment. For instance, each broker (a broker is a Kafka process) should be in its own data center, and a minimum of three brokers is required if you want the cluster to maintain operation if one Kafka instance fails. One aspect that has improved is the fact that ZooKeeper is no longer needed in a Kafka setup, reducing the number of VMs required for a production deployment.
Pitfall #3: Not managing event schema’s. Kafka is designed to handle data in the form of events, which can come from a variety of sources and change over time. However, if you’re not careful about how you handle schema changes, you can end up with a lot of issues. For example, if you change the schema for an event without updating all of the consumers that are subscribed to that event, you may end up with data that is not correctly processed or even lost.
Another thing to consider is schema’s changing over time. A good use case for storing historical events is for analytical purposes, however, this gets complicated very quickly. Downstream applications will need to understand how to process the schema of an event that has changed over time. Good tips to tackle these challenges are to avoid introducing breaking changes within one schema and to document a schema versioning system from the get-go.
Pitfall #4: A large cloud bill. While there are now excellent deployment options for Kafka, using one of the cloud offerings, can get expensive fast. Since Kafka is designed to handle very large quantities of data make sure you know the trade-offs of deploying a managed solution before you get started. Carefully configure your topics, partitions, and data retention rates to optimize your costs, or invest upfront and consider deploying an on-premise cluster, which can be cost-effective long term.
Pitfall #5: Do you need it? Finally, it’s important to carefully consider whether Kafka is the right tool for your specific use case. While it’s a powerful and flexible platform, it may not be the best choice for every scenario.
Kafka is a powerful tool, but it’s also quite complex. It has a lot of different components and configuration options, and it can be challenging to set up and manage effectively. It’s important to invest the time and resources necessary to properly understand Kafka and its architecture, as well as to properly configure and monitor your Kafka cluster. For example, if you’re only dealing with a small amount of data or you don’t need real-time processing capabilities, there may be simpler and more cost-effective alternatives available. It’s important to carefully evaluate your requirements and compare different options before making a decision.
Typically, data pipelines are built in a batch fashion. This means that data is shipped in fixed intervals, which are typically daily or even weekly intervals but can also be very small leading to micro-batches. For example, when running a data pipeline daily, a complete refresh of the dataset takes place in an ETL or ELT process. A modern approach to building (mostly) batched data pipelines might employ a modern data stack, of which a core component is a tool like DBT (data build tool). You can read more about this here.
Another modern approach to building data pipelines is to build a data pipeline that is real-time, which is where Kafka enters the mix. However, before deciding whether to build a real-time data pipeline or a batched version, consider the needs of the business and whether a real-time process is required. Real-time pipelines are still generally more complex and require more investment upfront to set up.
Kafka graduated from the Apache incubator in 2012 and since then adoption has only grown with good reason. It has very good support in all popular programming languages and very good interoperability with other tools. In a future blog post we will elaborate more about some of the tools that live in the ecosystem surrounding Kafka, including KSQLdb, an interesting database that allows you to leverage your real-time data streams using the KSQL declarative language.
In conclusion, Apache Kafka is a powerful distributed streaming platform that can be used for a wide range of use cases, from real-time data processing to batch processing. While there are certainly challenges associated with using Kafka, many of the common misconceptions about Kafka are unfounded. By understanding the capabilities and limitations of Kafka, organizations can make informed decisions about whether it is the right tool for their data processing needs.

Maximilian is a machine learning enthusiast, experienced software engineer, and co-founder of BiteStreams. In his free-time he listens to electronic music and is into photography.
Read moreEnjoyed reading this post? Check out our other articles.
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg