 Maximilian Filtenborg
Maximilian Filtenborg
Kom meer te weten over Apache Kafka in dit artikel over de grootste voordelen en misvattingen van Kafka.
Apache Kafka is een technologie met een behoorlijke hype. In deze post bekijken we Apache Kafka en proberen we inzicht te geven in wat Kafka is en misschien nog belangrijker, wat het niet is.
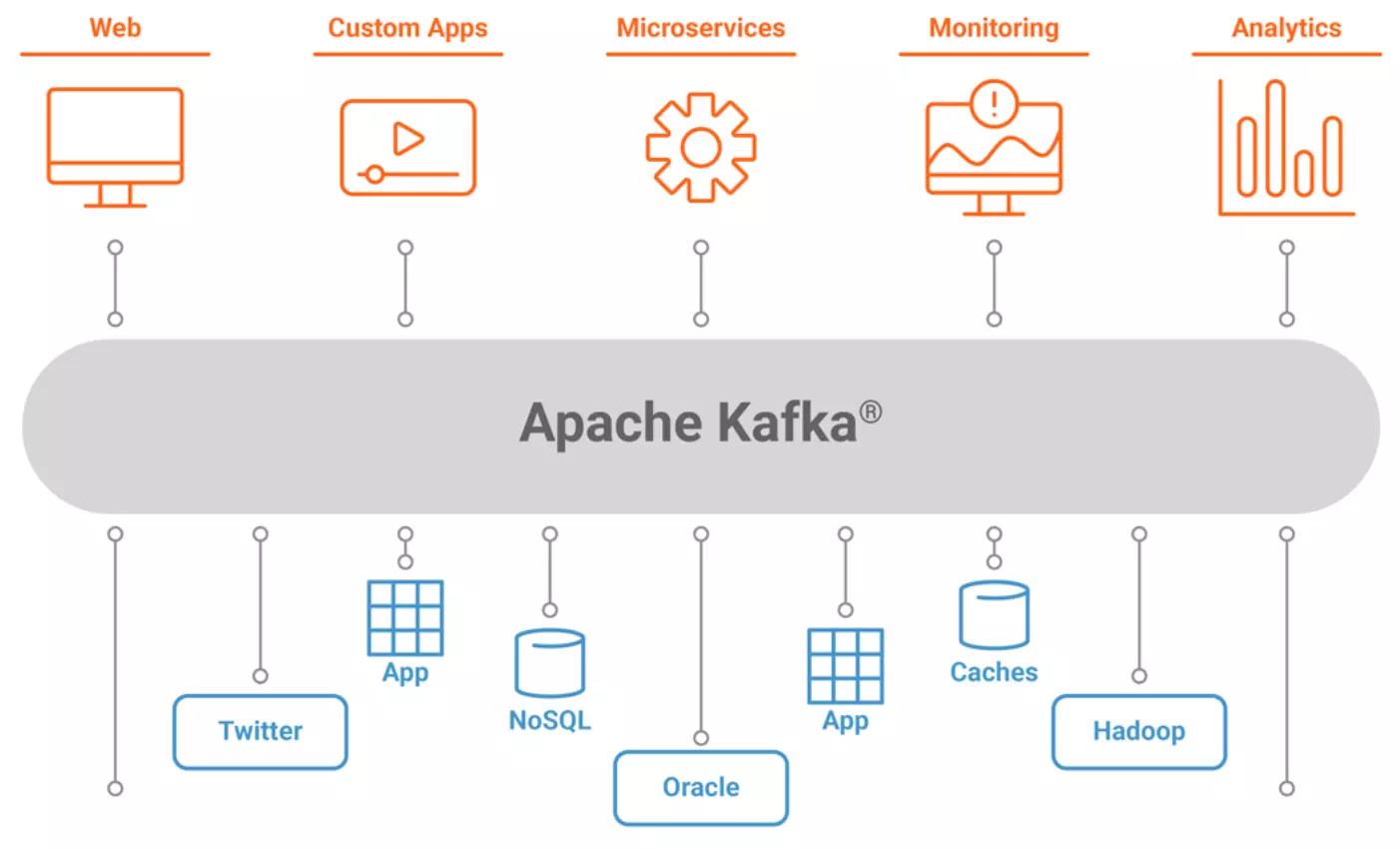
Apache Kafka is een open-source gedistribueerd streamingplatform dat is ontworpen om real-time datafeeds op een schaalbare en fouttolerante manier te verwerken. Het is de laatste jaren steeds populairder geworden, vooral in de context van big data en real-time dataverwerking.
Kafka, uitgevonden op LinkedIn, is een technologie die is voortgekomen uit bedrijven die de grenzen van gegevensverwerking verleggen. Het belangrijkste aspect van Kafka dat behoorlijk revolutionair is, is de hoeveelheid gegevens die het in realtime kan verwerken. In zekere zin is het een uitvinding die een logische vooruitgang is na de uitvinding van Hadoop. Hadoop was een technologie die werd uitgevonden om gigantische datasets te analyseren, maar op een zeer trage manier. Ter vergelijking: Kafka stelt ons in staat om vergelijkbare hoeveelheden gegevens te verwerken als een Hadoop MapReduce taak, maar dan in realtime. Deze analogie brengt ons echter maar zo ver, aangezien Kafka op zichzelf geen gegevens-verwerkings platform is.
Kortom, Kafka is een softwaretool om systemen aan elkaar te koppelen, of je nu een datawarehouse bouwt of een events gebaseerde microservices-architectuur, Kafka is een datastreamingplatform om te overwegen. Laten we eens kijken naar enkele voordelen van het gebruik van Kafka als datacommunicatieplatform:
Ontkoppelde communicatie. Omdat Kafka een producent-consumentmodel gebruikt voor het publiceren van gegevens, wordt de verbinding tussen twee willekeurige systemen op cruciale manieren ontkoppeld en robuuster. Aangezien beide applicaties alleen communiceren via het Kafka-protocol, hoeven geen van beiden te begrijpen hoe ze elkaars taal moeten spreken. Concreet betekent dit dat we systemen niet rechtstreeks hoeven te integreren, en alleen de producent nodig hebben om de relevante gegevens naar een Kafka-topic te publiceren. De consument van de datastroom kan dan besluiten om deze data op zijn eigen voorwaarden te consumeren. Een nadeel hiervan is dat een verzoek-antwoordmodel van communicatie ingewikkelder wordt, omdat er geen directe manier is om een antwoord te sturen op een bericht dat over een onderwerp is gepubliceerd. Natuurlijk zijn er manieren om dit ook met Kafka-topics te implementeren.
Robuuste en fouttolerante communicatie. Ten tweede, aangezien de datacommunicatie nu via een makelaar verloopt - het Kafka-streamingplatform, hebben we nu een zeer robuuste en fouttolerante communicatielijn, die van beide applicaties weinig aandacht vereist. Omdat de producent niet direct gekoppeld is aan de consument, kan de producent of de consument op elk moment offline gaan voor onderhoud. Wat er zal gebeuren, is dat de berichten tussen de applicaties gewoon een kleine vertraging hebben voordat ze door de consument worden verwerkt. Dit is veel moeilijker te verzekeren bij het uitvoeren van communicatie via REST-eindpunten. Een typische bug is het niet implementeren van een fallback in een situatie waarin de consument tijdelijk offline is, waardoor berichten niet worden ontvangen.
Naadloze integratie met veel systemen. Ten derde, omdat berichten nu in Kafka worden gepubliceerd en niet rechtstreeks tussen applicaties worden verzonden, kan elke applicatie besluiten om de berichtenstroom van een applicatie te gebruiken. Dit maakt het mogelijk om naadloos nieuwe integraties te bouwen, zolang de relevante en vereiste gegevens worden gepubliceerd. Dit wordt vooral relevant in grotere organisaties die te maken hebben met veel (micro-)services.
Hoge doorvoer. Kafka is ontworpen om grote hoeveelheden gegevens in realtime te verwerken, met een hoge doorvoer en lage latentie. Dit maakt het een ideaal platform voor het verwerken van grote datastromen, zoals die worden gegenereerd door IoT-apparaten of social media-platforms.
Schaalbaarheid. Kafka is een gedistribueerd platform en is vanaf het begin ontworpen om schaalbaar te zijn. Dit betekent dat het eenvoudig kan worden opgeschaald naarmate de datavolumes toenemen. Hierdoor kunnen zelfs de grootste organisaties hun Kafka-implementatie schalen naarmate hun vereisten voor gegevensverwerking toenemen.
Fouttolerant. Kafka is ontworpen om fouttolerant te zijn, met ingebouwde mechanismen voor het repliceren van gegevens over meerdere knooppunten in het cluster. Dit zorgt ervoor dat gegevens altijd beschikbaar zijn, zelfs bij hardwarestoringen of netwerkstoringen.
De architectuur van Kafka brengt veel voordelen met zich mee, maar er bestaat ook nogal wat verwarring over wat Kafka wel of niet is of wat het wel of niet kan. Hieronder staan 3 misvattingen die we vaak hebben gezien.
Misverstand #1: Kafka is een berichtensysteem. Een van de meest voorkomende misvattingen over Kafka is dat het een messaging-systeem is, zoals RabbitMQ of ActiveMQ. Hoewel Kafka kan worden gebruikt voor messaging, is het in wezen een gedistribueerd streamingplatform dat is ontworpen om real-time datafeeds te verwerken. Kafka slaat gegevens op in topics, die kunnen worden gezien als gegevensstromen die in realtime kunnen worden verwerkt. Hierdoor biedt het niet dezelfde flexibiliteit als bijvoorbeeld RabbitMQ.
Misverstand #2: Kafka is een database. Een andere veel voorkomende misvatting over Kafka is dat het databases of datawarehouses kan vervangen. Het opvragen van data vanuit Kafka is zeer beperkt, datastromen (topics in Kafka-nomenclatuur) worden van begin tot eind door consumenten geconsumeerd, als u een specifiek bericht moet ophalen, moet u vaak uw toevlucht nemen tot het scannen van de hele stroom van het begin tot het einde of beginnen bij een specifiek tijdstempel in de stream.
Hoewel Kafka kan worden gebruikt voor gegevensopslag, is het niet ontworpen als primaire gegevensopslag. In plaats daarvan is een van de beste use-cases van Kafka om het te gebruiken als een real-time datapijplijn die gegevens kan invoeren in databases of datawarehouses voor opslag en analyse.
Misverstand #3: Gegevens binnen Kafka zijn kortstondig. Enkele van de interessante use-cases van Kafka worden mogelijk gemaakt door het gebruik van onderwerpen die gegevens voor altijd bewaren. Hoewel berichten in Kafka standaard wel een TTL hebben geconfigureerd, kan dit ook serverbreed of per topic worden uitgeschakeld en geconfigureerd. Kafka is zo ontworpen dat een zeer groot onderwerp geen nadelen heeft voor up-to-date consumenten, wat betekent dat dit het Kafka-cluster niet zal vertragen. Dit maakt de implementatie van bepaalde patronen mogelijk, bijvoorbeeld het opslaan van historische updates van een applicatie binnen Kafka, voor gebruik door andere consumenten op een later tijdstip.
Apache Kafka is een tool die erg goed is in wat het doet, maar voordat je besluit om Apache Kafka te gebruiken, moet je volledig begrijpen waar je aan begint. Een van de nadelen van Kafka is dat het een complexe tool kan zijn. Om de vruchten te plukken van het gebruik van Kafka, moet men hun Kafka-instantie afstemmen en configureren volgens hun behoeften. Hieronder schetsen we belangrijke details wanneer u besluit om Kafka in te schakelen voor uw zakelijke behoeften.
Valkuil #1: partities niet begrijpen. Het aantal partities in een Kafka-onderwerp heeft een grote invloed op de prestaties en schaalbaarheid. Het aantal partities bepaalt het aantal consumenten dat u van één onderwerp (gegevensstroom) tegelijk kunt hebben, dit betekent dat het het maximale aantal parallelle processen begrenst dat u kunt hebben. Net zo belangrijk is het feit dat berichten slechts binnen één partitie worden geordend, dit is een grote factor waardoor Kafka zo goed kan schalen. Als ordening belangrijk is voor uw berichten (wat vaak het geval is), moet de toepassing die verbinding maakt met uw Kafka-onderwerp dit aspect zorgvuldig overwegen.
Evenzo, aangezien het aantal partities het aantal parallelle consumenten bepaalt, is het een belangrijke instelling om goed te configureren. Het is niet zo eenvoudig als het instellen van het aantal partities op een zeer hoog aantal, aangezien het hebben van te veel partities ook nadelen heeft in termen van complexiteit en extra overhead. Het is belangrijk om de juiste balans te vinden op basis van uw specifieke use case en workload.
Valkuil #2: Een Kafka-instantie met één instance deployen. Als er iets een antipatroon is, dan is dit het waarschijnlijk wel. Het implementeren van een Kafka-instantie met één knooppunt betekent dat u de meeste van zijn belangrijkste sterke punten verliest, zoals hoge beschikbaarheid, schaalbaarheid en fouttolerantie. Bovendien is de fouttolerantie van Kafka pas echt gegarandeerd bij een doordachte deployment. Elke broker (een broker is een Kafka-proces) moet zich bijvoorbeeld in zijn eigen datacenter bevinden en er zijn minimaal drie brokers vereist als u wilt dat het cluster blijft werken als één Kafka-instantie uitvalt. Een verbeterd aspect is het feit dat ZooKeeper niet langer nodig is in een Kafka-configuratie, waardoor er minder VM’s nodig zijn voor een productie-implementatie.
Valkuil #3: Evenementschema’s niet beheren. Kafka is ontworpen om gegevens te verwerken in de vorm van gebeurtenissen, die uit verschillende bronnen kunnen komen en in de loop van de tijd kunnen veranderen. Als u echter niet voorzichtig bent met de manier waarop u met schemawijzigingen omgaat, kunt u met veel problemen te maken krijgen. Als u bijvoorbeeld het schema voor een gebeurtenis wijzigt zonder alle consumenten bij te werken die op die gebeurtenis zijn geabonneerd, kunt u eindigen met gegevens die niet correct worden verwerkt of zelfs verloren gaan.
Een ander ding om te overwegen is dat schema’s in de loop van de tijd veranderen. Een goede use-case voor het opslaan van historische gebeurtenissen is voor analytische doeleinden, maar dit wordt erg snel gecompliceerd. Downstream-applicaties moeten begrijpen hoe ze het schema moeten verwerken van een gebeurtenis die in de loop van de tijd is veranderd. Goede tips om deze uitdagingen aan te gaan, zijn om te voorkomen dat er binnen één schema ingrijpende wijzigingen worden aangebracht en om vanaf het begin een schemaversiesysteem te documenteren.
Valkuil #4: Een grote cloudrekening. Hoewel er nu uitstekende deployment-opties voor Kafka zijn, kan het gebruik van een van de cloudaanbiedingen snel duur worden. Aangezien Kafka is ontworpen om zeer grote hoeveelheden gegevens te verwerken, moet u ervoor zorgen dat u weet wat de nadelen zijn van het implementeren van een beheerde oplossing voordat u aan de slag gaat. Configureer uw onderwerpen, partities en dataretentiepercentages zorgvuldig om uw kosten te optimaliseren, of investeer vooraf en overweeg de implementatie van een on-premise cluster, wat op de lange termijn kosteneffectief kan zijn.
Valkuil #5: Heb je het nodig? Ten slotte is het belangrijk om zorgvuldig te overwegen of Kafka de juiste tool is voor uw specifieke gebruikssituatie. Hoewel het een krachtig en flexibel platform is, is het misschien niet de beste keuze voor elk scenario.
Kafka is een krachtig hulpmiddel, maar het is ook vrij complex. Het heeft veel verschillende componenten en configuratie-opties, en het kan een uitdaging zijn om het effectief in te stellen en te beheren. Het is belangrijk om de tijd en middelen te investeren die nodig zijn om Kafka en zijn architectuur goed te begrijpen, en om uw Kafka-cluster goed te configureren en te bewaken. Als u bijvoorbeeld slechts met een kleine hoeveelheid gegevens te maken heeft of als u geen realtime verwerkingsmogelijkheden nodig heeft, zijn er wellicht eenvoudigere en meer kosteneffectieve alternatieven beschikbaar. Het is belangrijk om uw vereisten zorgvuldig te evalueren en verschillende opties te vergelijken voordat u een beslissing neemt.
Datapipelines worden doorgaans in batches gebouwd. Dit betekent dat gegevens met vaste intervallen worden verzonden, meestal dagelijkse of zelfs wekelijkse intervallen, maar die ook zeer klein kunnen zijn, wat leidt tot microbatches. Bij het dagelijks uitvoeren van een datapijplijn vindt bijvoorbeeld een volledige vernieuwing van de dataset plaats in een ETL- of ELT-proces. Een moderne benadering van het bouwen van (meestal) gegroepeerde datapijplijnen zou een moderne datastack kunnen gebruiken, waarvan een kerncomponent een tool is zoals DBT (data build tool). Je kunt hier hier meer over lezen.
Een andere moderne benadering van het bouwen van datapijplijnen is het bouwen van een datapijplijn die realtime is, en dat is waar Kafka in de mix komt. Voordat u echter beslist of u een real-time datapijplijn of een batchversie wilt bouwen, moet u rekening houden met de behoeften van het bedrijf en of een real-time proces vereist is. Realtime pijplijnen zijn over het algemeen nog steeds complexer en vereisen vooraf meer investeringen om op te zetten.
Kafka kwam in 2012 uit de Apache-incubator en sindsdien is de adoptie alleen maar gegroeid, met een goede reden. Het heeft zeer goede ondersteuning in alle populaire programmeertalen en goede interoperabiliteit met andere tools. In een toekomstige blogpost zullen we meer uitweiden over enkele van de tools die leven in het ecosysteem rond Kafka, waaronder KSQLdb, een interessante database waarmee je je real-time datastromen kunt benutten met behulp van de KSQL-declaratieve taal.
Kortom, Apache Kafka is een krachtig gedistribueerd streamingplatform dat kan worden gebruikt voor een breed scala aan use-cases, van realtime gegevensverwerking tot batchverwerking. Hoewel er zeker uitdagingen zijn verbonden aan het gebruik van Kafka, zijn veel van de algemene misvattingen over Kafka ongegrond. Door de mogelijkheden en beperkingen van Kafka te begrijpen, kunnen organisaties weloverwogen beslissingen nemen over de vraag of het de juiste tool is voor hun behoeften op het gebied van gegevensverwerking.

Maximilian is een liefhebber van machine learning, ervaren software-engineer en mede-oprichter van BiteStreams. In zijn vrije tijd luistert hij naar elektronische muziek en houdt hij zich bezig met fotografie en hiken.
Meer lezenEnjoyed reading this post? Check out our other articles.
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg
 Donny Peeters
Donny Peeters
Wordt meer datagedreven met BiteStreams en laat de concurrentie achter je.
Contacteer ons