 Donny Peeters
Donny Peeters
Save yourself from inconsistency and complex migration plans by watching out for these data modeling issues.
Over the years as a data engineer working with operational and analytical databases, you find yourself regretting decisions you made in the past. Why did I introduce this ill-supported dependency? Why did I write my own crappy data orchestration code? Why did I think buying a brown pullover was a good idea?
Luckily for us, code (and ugly sweaters) can be thrown away. But for production data, backward and forward compatibility can be a real pain to deal with: there are no migrations that magically provide the data you were not saving, or asks your users for a new bio with half of the available characters.
Therefore, taking shortcuts or turning a blind eye is often too tempting. How many times do you end up fighting a legacy data model in the data warehouse, and every insane structure is justified with a shrug and “it’s too late to change that now”? Like the Christmas picture of you in that pullover, data confronts you with your mistakes long after you’ve rectified them.
As this blog post advocates:
Your data is the most important part of your system. I’ve seen a lot of systems where hope was the primary mechanism of data integrity. […] Dealing with this [dirty] data in the future can become a nightmare. Just remember, your data will likely long outlive your codebase. Spend energy keeping it orderly and clean.
Hence, with this two-part blog series on data modeling, I will try to let less of this energy go to waste. In this first post, I am sharing 10 (operational) data modeling mistakes either I myself made, or I’ve seen others make. In the end, hopefully this can serve as a guide to get the data model “right” as soon as possible, saving the operational system from complex migrations and the data warehouse from dreadful backfills. In a next post, I will tackle dimensional modeling pitfalls so your BI dashboards stay consistent and performant.
I added blocks with catchphrases to watch out for, so you can spot these design smells early:
Writing tests only slows us down!
When you hear one of these, object blindly.
But how will that perform for our monthly exports when we have millions of rows?
I’ll just add this CSV export button for the data scientists to use.
Your most important task as a modeler is meeting business requirements. Unless those requirements suck. User don’t always know what they want, especially if those users are data analysts connecting to your operational database. It might sound sensible to choose performance over a bit of consistency as in Tip 2 and 6, but for operational systems you want to be able to add records in all parts of the application. Performance can often be dealt with by scoping the amount of data regular users see or receive properly, consistency and clarity in the model being a lot more important.
Your most important task as a modeler is meeting business requirements. Unless those requirements suck.
If, however, your applications starts to frequently perform full table scans, chances are it is solving analytical needs. If this means often doing a handful of unique queries that infrequently change, a relative easy fix would be application-level caching. If you provide several dashboards, graphs and the ability to filter them dynamically, it might be time to consider offloading these to a data warehouse. With tools such as Duckdb, Clickhouse, and the modern data stack, it has become quite interesting to invest in a data warehouse.
We should make sure that if we change the name field, we do it for all rows with the same value…
You are not allowed to change that model because it represents an append-only record.
Most modelers have heard of 3NF. This cornerstone of database schema design guarantees your database will remain semantically consistent by letting each record in your database provide the right amount of information of the entity. While there are many definitions of 3NF online, the most common pitfall is not normalizing your data model well enough. Adding fields is just easier than creating tables. Critically assess the way your data might change or get added to get a grasp of potential inconsistencies, for example:
But it could be the other way around as well:
Carefully take your own requirements into account.
We should raise an exception when model.field is not in some_list.
We can add a cronjob that cleans up all invalid some_field by setting them to null.
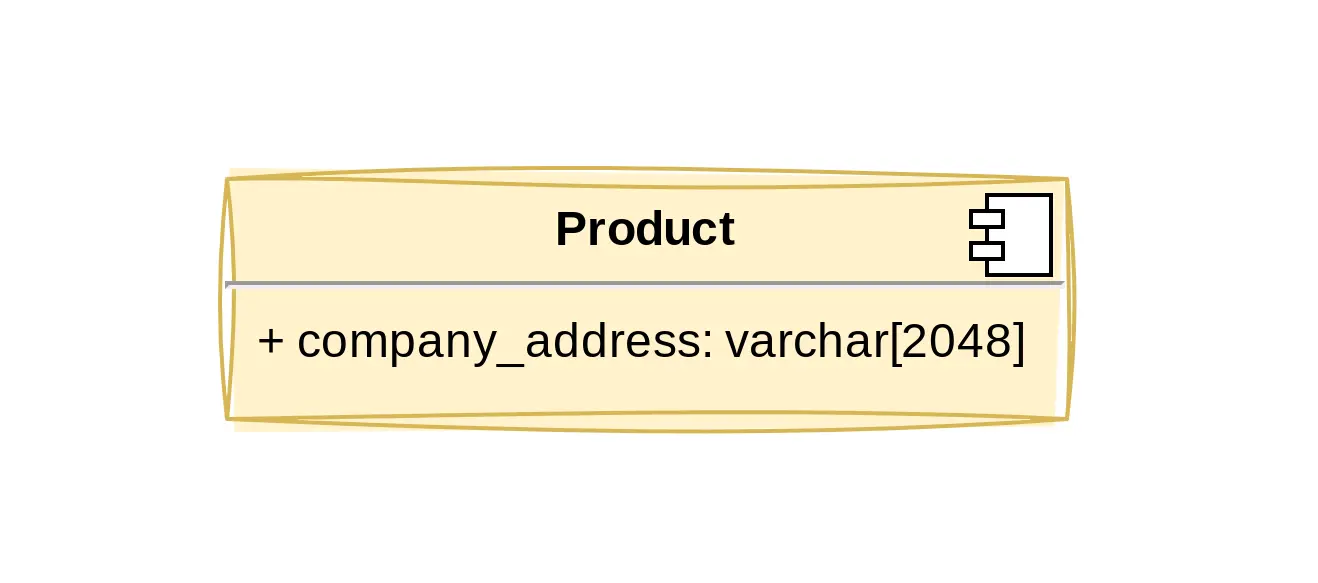
We all love filters. Show me Shoes from Adidas that are blue and made from leather. There are several reasons these fields should not just be free text fields:
Watch out for these scenario’s and consider using enumerated types instead. This enforces the choices for a field to a predefined list at the database level. Life is a lot easier when you can trust the integrity of your data, especially if these fields are commonly used for filtering: by using integers for these choices at the database level it can give an easy performance boost over varchar’s.
So for this module we always need to check if animal.specie == Specie.COW
A natural follow-up on the previous point: what if the category shoes actually has a lot of custom fields and requires specialized logic in the code? If shoes are a central part of your domain and you consider it part of your Domain Model, you should consider creating a separate database model for it.
These can be hard to spot and drawing the line of when to specialize and when to generalize is notoriously hard and case-specific. As a rule of thumb you could:
Oh you were talking about synonym this whole time?
Actually, booking.total_amount is the same as reservation.price
So the conf table actually contains all user_preferences?
Hopefully this speaks for itself. A lot of small issues in larger scale organizations stem from this kind of miscommunication. Choices about naming should not be made solely by modelers or software engineers. They must agree with the language used by non-technical teams as well. As Eric Evans once wrote about such an ubiquitous language:
Domain experts should object to terms or structures that are awkward or inadequate to convey domain understanding; developers should watch for ambiguity or inconsistency that will trip up design.
Don’t hesitate to resolve naming issues as soon as they appear, even if it affects large parts of the code and database. A system that you cannot talk naturally about is a system you cannot explain.
So the way to optimize this is adding a total_orders field on the product model.
We can just add a cronjob to update field x using field y every hour.
Perhaps […] CREATE TRIGGER […]
We’ve all seen them or felt the temptation at some point: fields that are the direct result of a subquery. This is usually out of performance considerations. As was pointed out in Tip 1, this can be the result of solving an analytical use-case. But also irregular access patterns, lack of a proper scope for the current user in the UI, or overestimating how much data a user needs to see can be the cause. And then you might want to look into a proper caching strategy first.
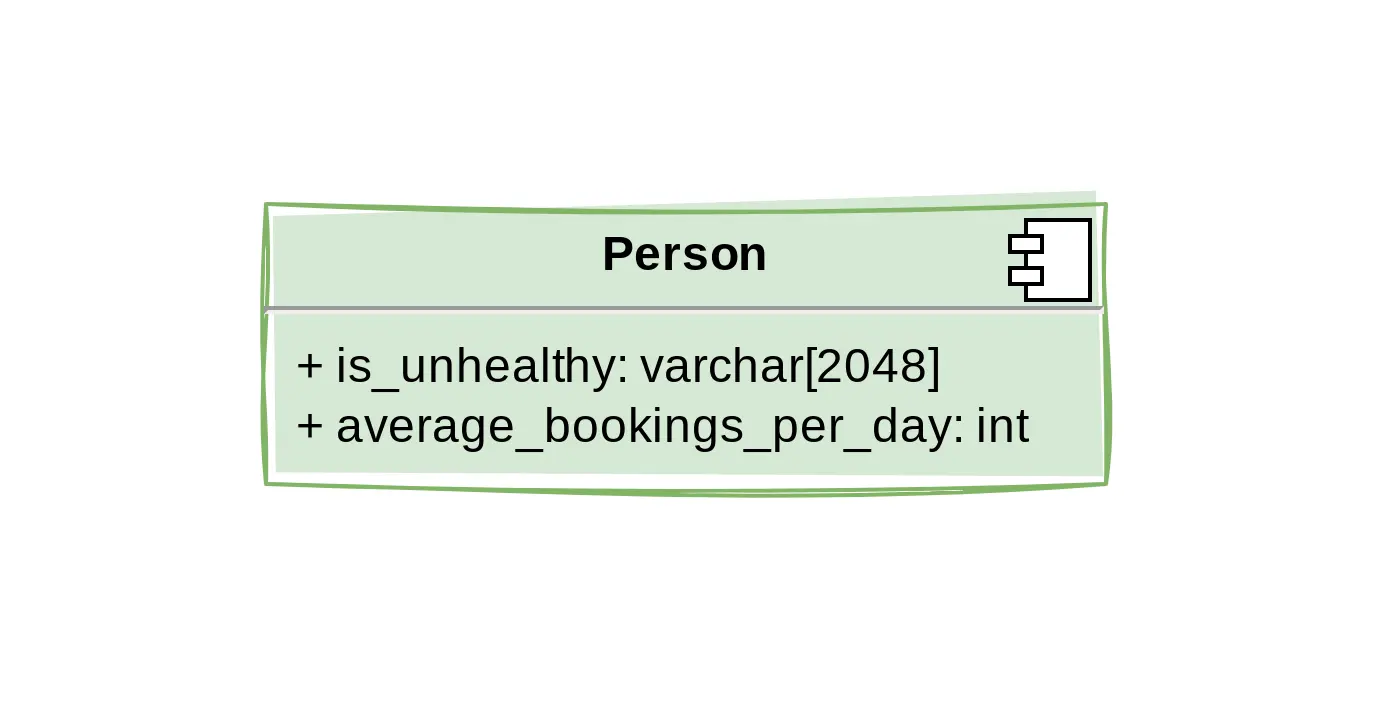
Sometimes, these fields are added because it is not obvious these values can be computed at query-time. If you want to mark people with is_unhealthy = True depending on this formula:
|
|
just compute this in the query itself and let the application worry about the definition of is_unhealthy. When you have to join more and more tables and start adding advanced transformations functions, this can seem daunting - and will these joins actually perform when we have millions… Oh, wait. Remember, there is often no real reason to look at more than 10 to 20 data points as a regular user, which leaves room for more involved operations at query time.
In short, you should be very skeptical if your intuition is telling you to introduce triggers or scheduled transformations. Instead, try to look for ways to make the values of these fields easier to query. The source of the problem is often in the model itself.
But what about X‘s that have multiple Y‘s?
Not all model relationship are trivial. Does every country have a capital or does every capital have a country? Does every user have account_details or is it the other way around?
Of course, for one-to-many relationships it is quite easy to set the right reference. But still people too often are tempted to revert this relationship into an array field. Think about current and future cardinality between your models and avoid complex migrations later on.
But model X has almost the exact same fields as model Y!
Oh glorious inheritance! Thou polymorphism shall not be used in vain! And thou shall especially not be used as the sole tool for code reusage. We would be saving each other hours of confusion and refactoring if we stop thinking DRY implies extending parent classes.
And this holds for database models as well. I’ve personally seen instances where database models were abused so a critical review of the domain model could be avoided. Say we are building apartment rental software and introduce an apartment_building model, isn’t this just a apartment with extra properties? Perhaps an is_building field? You could reuse the address models, perhaps make it easy to cluster an account manager portfolio.
But then you try to add hierarchy and start doing self-joins, add sparse building-specific fields and before you know it, you’re fighting your own model.
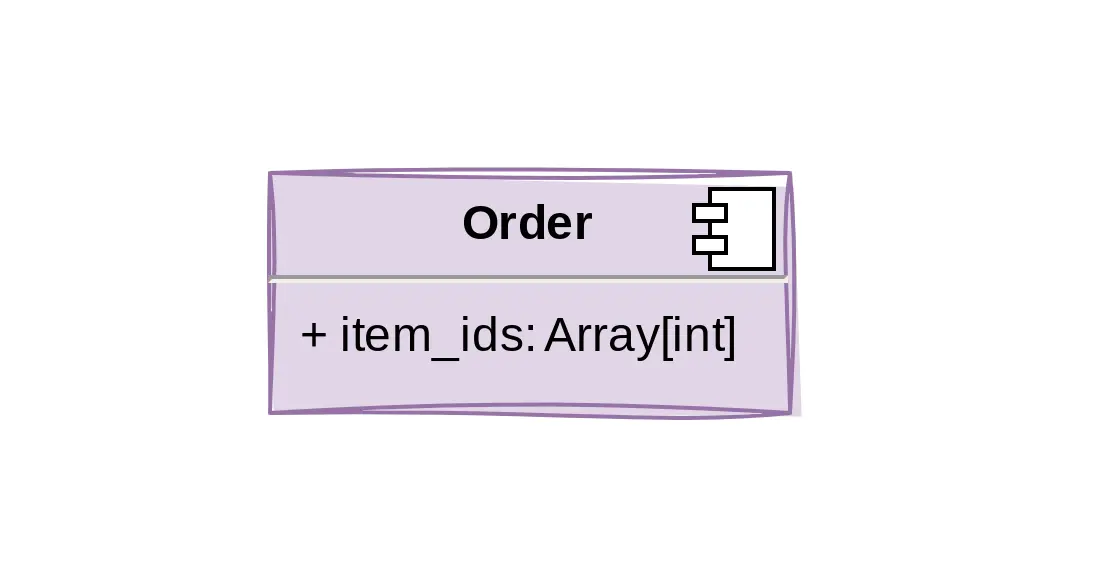
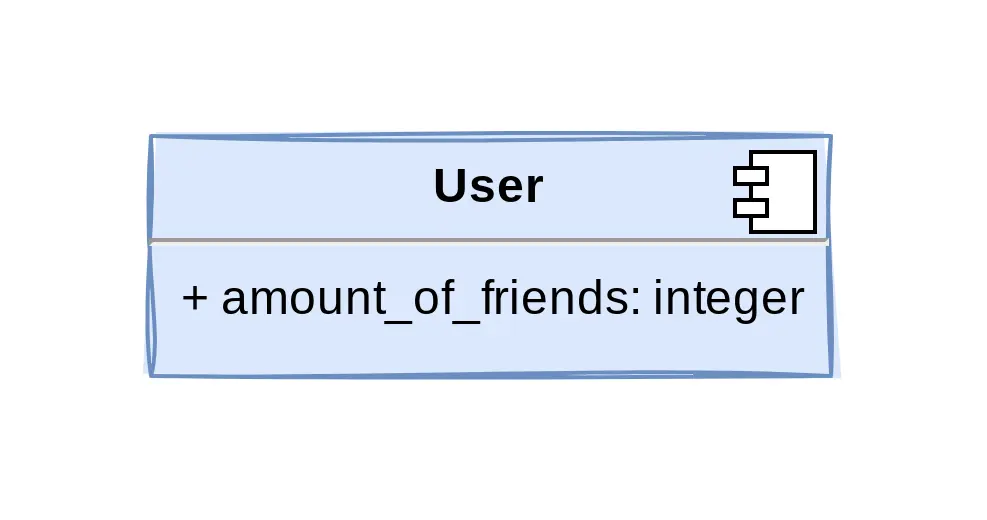
This entity has a set of related values? Let’s just create an array field.
We’re never going to query these values anyway.
As tempting as the lack of joins sounds, there is no field type more likely to result in regret than the array. Although they obviously have their use, you want to be cognizant of the fact that it is easy to mistake it as an excuse to avoid many-to-many relationships. How to know if you’re misusing them? Ask yourself many times: will I ever filter on these values? Will these values ever require more information? Do I need to group rows that contain a specific value in its array?
If any of the answers is yes, think long and hard before adding that array field. Array fields should be used when the arrays are mostly accessed as a whole and contain little semantic value, not for corner cutting.
I don’t know what that field means in the context of this model..
So to create a Y, I first have to create a Q, X and a P?
This is as applicable to data modeling as general OOP. I’ve seen schema’s where (multiple) domain models have a field pointing to the job that generated it. Although this relationship points in the right direction in terms of cardinality, you might quickly spot possible implementation challenges with this model. What about models that are added manually? What if new jobs find the same object? What if we delete models? Will this affect integrity if we consider jobs with 0 results to have failed?
You can see where this can go wrong. Spotting this modeling smell comes with experience though. It starts with having to do the same operations to create, update or query you models. It ends up in not being able to deliver features timely or not being able to fix some issues at all. Good data engineers build features by introducing new data models. Great data engineers create a model where these features are self-evident.
Good data engineers build features by introducing new data models. Great data engineers create a model where these features are self-evident.
I liked that brown sweater initially. (I like a lot of my ideas initially.) But some decision tend to last, especially bad ones. People at DoorDash spent years on migrations according to this talk, appropriately titled “Migrations - The Hardest Actual Problem in Computer Science”. Fixing today’s issues is usually only a third of the problem.
Give me a legacy project with garbage code but a solid data model, and I’ll lay out a plan to refactor it to a maintainable system with minimal impact. Give me a clean legacy project built on top of a garbage data model, and brace yourself for migrations, domain modeling sessions, probable data loss and most importantly: impact on users.
Whether it’s clothing or data modeling, not messing it up takes time and effort. Properly weigh trade-offs and try to “design it twice” whenever possible. And of course: keep an eye out for the signs of these 10 modeling sins.

Donny is a mathematician who started freelancing as a software/data engineer before co-founding BiteStreams. He can quickly spot design quirks and adapt systems to business needs. In his free-time he likes to work out, read and grab a drink with friends.
About usEnjoyed reading this post? Check out our other articles.
Donny Peeters
 Maximilian Filtenborg
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg
Get more data-driven with BiteStreams, and leave the competition behind.
Contact us