 Maximilian Filtenborg
Maximilian Filtenborg
Bespaar jezelf inconsistentie en complexe migratieplannen door op te letten voor deze problemen bij data modeling.
In de loop der jaren, werkend als gegevensingenieur met operationele en analytische databases, betrap je jezelf erop spijt te hebben van beslissingen die je in het verleden hebt genomen. Waarom introduceerde ik deze slecht ondersteunde afhankelijkheid? Waarom schreef ik mijn eigen waardeloze gegevensorkestratiecode? Waarom dacht ik dat het een goed idee was om een bruine trui te kopen?
Gelukkig voor ons kunnen code (en lelijke truien) worden weggegooid. Maar voor productiegegevens kunnen achterwaartse en voorwaartse compatibiliteit een echte uitdaging zijn: er zijn geen migraties die magisch de gegevens verschaffen die je niet aan het opslaan was, of die je gebruikers vragen om een nieuwe biografie met de helft van de beschikbare tekens.
Daarom is het verleidelijk om shortcuts te nemen of een oogje dicht te knijpen vaak te groot. Hoe vaak beland je in een gevecht met een verouderd gegevensmodel in het datawarehouse, en wordt elke waanzinnige structuur gerechtvaardigd met een schouderophalen en “het is nu te laat om dat nog te veranderen”? Net als de kerstfoto van jou in die trui, confronteert data je met je fouten lang nadat je ze hebt rechtgezet.
Zoals deze blogpost bepleit:
Je gegevens zijn het belangrijkste deel van je systeem. Ik heb veel systemen gezien waar hoop het belangrijkste mechanisme van gegevensintegriteit was. […] Het omgaan met deze [vuile] gegevens in de toekomst kan een nachtmerrie worden. Onthoud gewoon, je gegevens zullen waarschijnlijk veel langer overleven dan je codebase. Besteed energie aan het ordelijk en schoon houden ervan.
Daarom zal ik met deze tweedelige blogserie over gegevensmodellering proberen minder van deze energie te verspillen. In deze eerste post deel ik 10 (operationele) fouten in gegevensmodellering die ik zelf heb gemaakt, of die ik anderen heb zien maken. Uiteindelijk kan dit hopelijk dienen als een gids om het gegevensmodel zo snel mogelijk “goed” te krijgen, waardoor het operationele systeem wordt bespaard van complexe migraties en het datawarehouse van verschrikkelijke backfills. In een volgende post zal ik ingaan op valkuilen bij dimensionale modellering, zodat je BI-dashboards consistent en prestatiegericht blijven.
Ik heb blokken toegevoegd met slogans om op te letten, zodat je deze ontwerpfouten vroegtijdig kunt herkennen:
Tests schrijven vertraagt ons alleen maar!
Als je een van deze hoort, verzet je er dan blindelings tegen.
Maar hoe presteert dat voor onze maandelijkse exports wanneer we miljoenen rijen hebben?
Ik voeg gewoon deze CSV-exportknop toe voor de datascientists om te gebruiken.
Je belangrijkste taak als modelleur is het voldoen aan zakelijke vereisten. Tenzij die vereisten waardeloos zijn. Gebruikers weten niet altijd wat ze willen, vooral als die gebruikers data-analisten zijn die verbinding maken met je operationele database. Het lijkt misschien verstandig om voor prestaties te kiezen ten koste van een beetje consistentie zoals bij Tip 2 en 6, maar voor operationele systemen wil je records kunnen toevoegen in alle delen van de applicatie. Prestaties kunnen vaak worden aangepakt door de hoeveelheid data die reguliere gebruikers zien of ontvangen goed te begrenzen, consistentie en duidelijkheid in het model zijn veel belangrijker.
Je belangrijkste taak als modelleur is het voldoen aan zakelijke vereisten. Tenzij die vereisten waardeloos zijn.
Als je applicatie echter vaak volledige tabelscans begint uit te voeren, is de kans groot dat het analytische behoeften oplost. Als dit betekent dat je vaak een handvol unieke queries uitvoert die zelden veranderen, zou een relatief eenvoudige oplossing caching op applicatieniveau zijn. Als je meerdere dashboards, grafieken en de mogelijkheid om ze dynamisch te filteren biedt, is het misschien tijd om deze over te hevelen naar een datawarehouse. Met tools zoals Duckdb, Clickhouse en de moderne data stack, is het tegenwoordig behoorlijk interessant om te investeren in een datawarehouse.
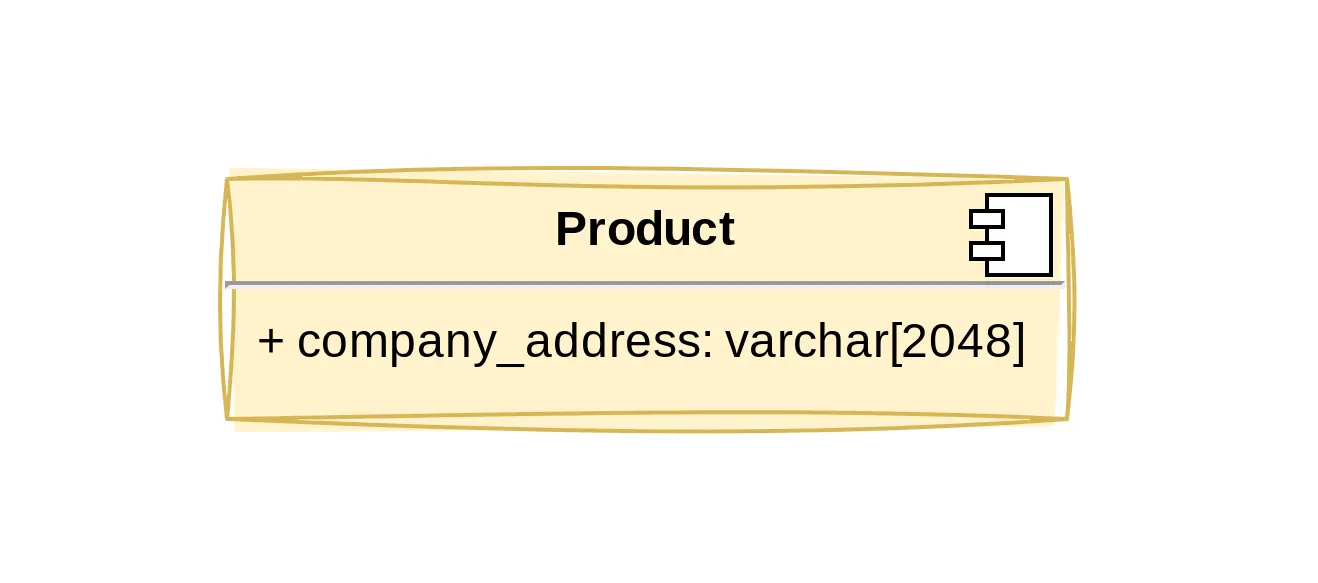
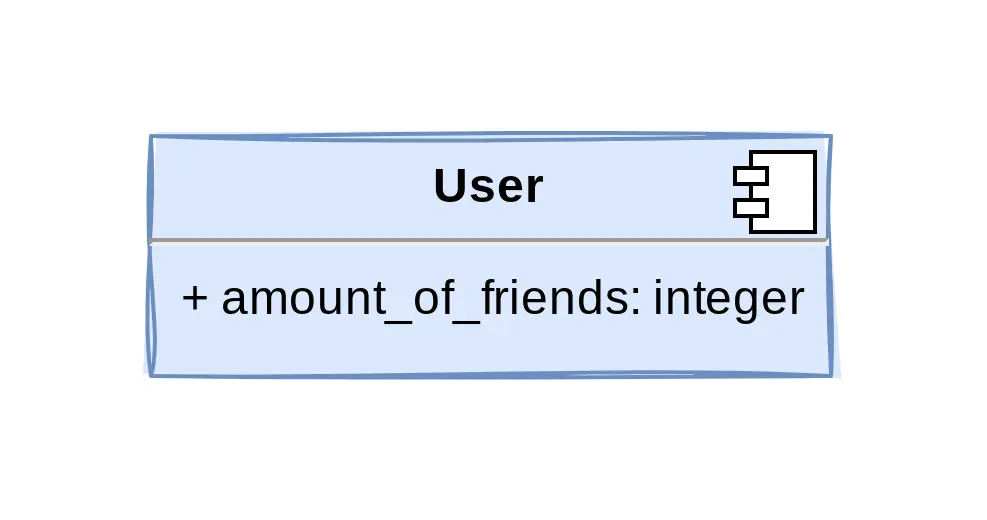
We moeten ervoor zorgen dat als we het veld naam wijzigen, we dit doen voor alle rijen met dezelfde waarde…
Je mag dat model niet wijzigen omdat het een record is dat alleen kan worden toegevoegd.
De meeste modelleurs hebben gehoord van 3NF. Deze hoeksteen van het ontwerp van databaseschema’s garandeert dat je database semantisch consistent blijft door elk record in je database de juiste hoeveelheid informatie van de entiteit te laten verstrekken. Hoewel er veel definities van 3NF online zijn, is de meest voorkomende valkuil het niet goed normaliseren van je gegevensmodel. Velden toevoegen is gewoon eenvoudiger dan tabellen maken. Beoordeel kritisch hoe je gegevens kunnen veranderen of worden toegevoegd om een idee te krijgen van mogelijke inconsistenties, bijvoorbeeld:
Maar het kan ook andersom zijn:
Houd rekening met je eigen vereisten.
We moeten een uitzondering genereren wanneer model.field niet in some_list staat.
We kunnen een cronjob toevoegen die alle ongeldige some_field opruimt door ze in te stellen op null.
We houden allemaal van filters. Toon me schoenen van Adidas die blauw zijn en gemaakt van leer. Er zijn verschillende redenen waarom deze velden niet zomaar vrije tekstvelden zouden moeten zijn:
Let op deze scenario’s en overweeg in plaats daarvan geënumereerde typen te gebruiken. Dit dwingt de keuzes voor een veld af naar een vooraf gedefinieerde lijst op het databaseniveau. Het leven is veel eenvoudiger wanneer je de integriteit van je gegevens kunt vertrouwen, vooral als deze velden vaak worden gebruikt voor filtering: door integers te gebruiken voor deze keuzes op het databaseniveau kan het een eenvoudige prestatieverbetering opleveren ten opzichte van varchar’s.
Dus voor deze module moeten we altijd controleren of animal.specie == Specie.COW
Een natuurlijk vervolg op het vorige punt: wat als de categorie schoenen eigenlijk veel aangepaste velden heeft en gespecialiseerde logica in de code vereist? Als schoenen een centraal onderdeel zijn van je domein en je beschouwt het als onderdeel van je Domeinmodel, dan moet je overwegen een apart database-model ervoor te maken.
Dit kan moeilijk te herkennen zijn, en de grens trekken tussen specialiseren en generaliseren is berucht moeilijk en afhankelijk van de situatie. Als vuistregel zou je kunnen:
Oh, je had het de hele tijd over synoniem?
Eigenlijk is booking.total_amount hetzelfde als reservation.price
Dus de conf-tabel bevat eigenlijk alle user_preferences?
Hopelijk spreekt dit voor zich. Veel kleine problemen in grotere organisaties komen voort uit dit soort miscommunicatie. Beslissingen over benamingen moeten niet uitsluitend worden genomen door modelleurs of software-ingenieurs. Ze moeten overeenstemmen met de taal die wordt gebruikt door niet-technische teams. Zoals Eric Evans ooit schreef over zo’n alomtegenwoordige taal:
Domeinexperts moeten bezwaar maken tegen termen of structuren die onhandig of onvoldoende zijn om het domeinbegrip over te brengen; ontwikkelaars moeten letten op ambiguïteit of inconsistentie die het ontwerp kan verstoren.
Aarzel niet om benamingskwesties op te lossen zodra ze zich voordoen, zelfs als dit grote delen van de code en database beïnvloedt. Een systeem waarover je niet natuurlijk kunt praten, is een systeem dat je niet kunt uitleggen.
Dus de manier om dit te optimaliseren is het toevoegen van een veld total_orders aan het product-model.
We kunnen gewoon een cronjob toevoegen om veld x te updaten met behulp van veld y elk uur.
Misschien […] CREATE TRIGGER […]
We hebben ze allemaal gezien of hebben op een bepaald moment de verleiding gevoeld: velden die het directe resultaat zijn van een subquery. Dit gebeurt meestal vanwege prestatieoverwegingen. Zoals werd opgemerkt in Tip 1, kan dit het gevolg zijn van het oplossen van een analytisch gebruiksscenario. Maar ook onregelmatige toegangspatronen, gebrek aan een juiste scope voor de huidige gebruiker in de UI, of overschatting van hoeveel gegevens een gebruiker moet zien, kunnen de oorzaak zijn. En dan wil je misschien eerst naar een degelijke cachingstrategie kijken.
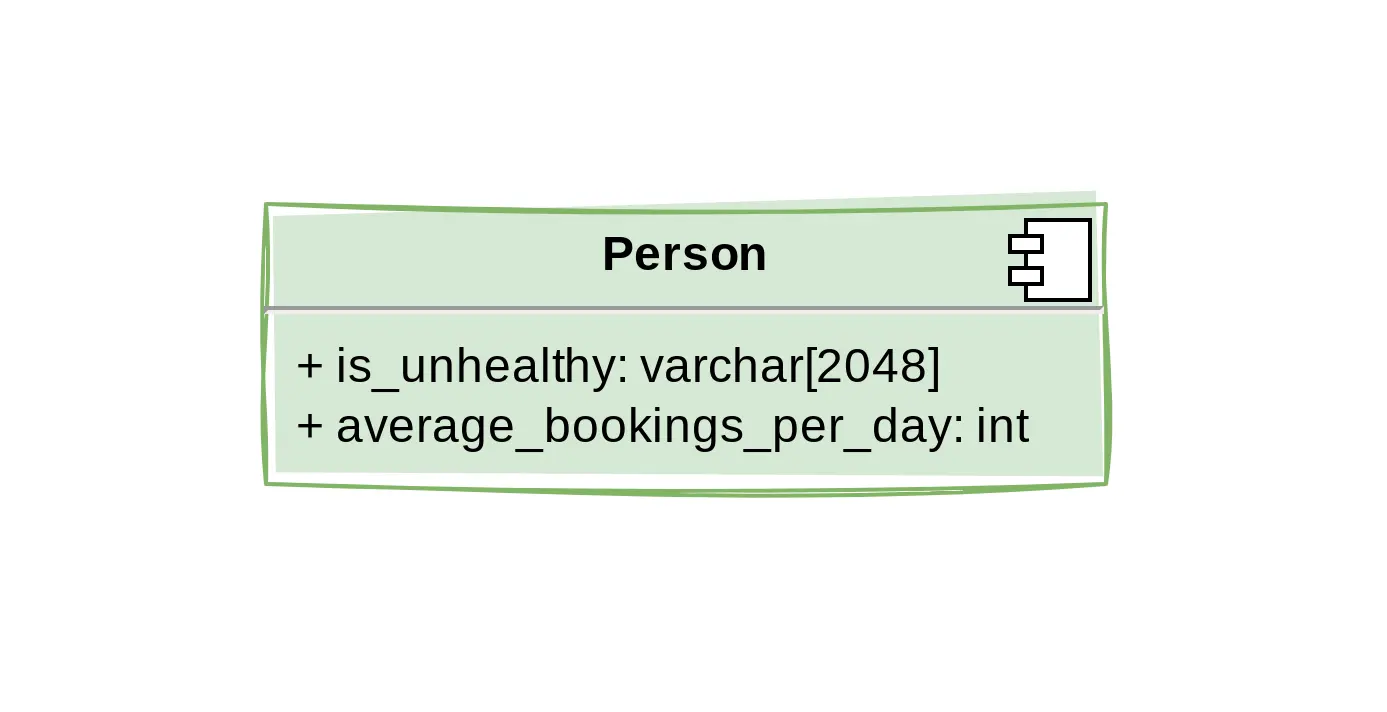
Soms worden deze velden toegevoegd omdat het niet duidelijk is dat deze waarden bij querytijd kunnen worden berekend. Als je bijvoorbeeld mensen met is_unhealthy = True wilt markeren op basis van deze formule:
|
|
bereken dit dan gewoon in de query zelf en laat de applicatie zich zorgen maken over de definitie van is_unhealthy. Wanneer je meer en meer tabellen moet samenvoegen en geavanceerde transformatiefuncties moet toevoegen, kan dit ontmoedigend lijken - en zullen deze joins eigenlijk presteren als we miljoenen hebben… Oh wacht. Onthoud, er is vaak geen echte reden om naar meer dan 10 tot 20 gegevenspunten te kijken als een reguliere gebruiker, wat ruimte laat voor meer betrokken bewerkingen bij querytijd.
Kortom, wees zeer sceptisch als je intuïtie je vertelt om triggers of geplande transformaties in te voeren. Probeer in plaats daarvan manieren te vinden om de waarden van deze velden gemakkelijker te bevragen. De bron van het probleem ligt vaak in het model zelf.
Maar wat dan met X‘s die meerdere Y‘s hebben?
Niet alle modelrelaties zijn triviaal. Heeft elk land een hoofdstad of heeft elke hoofdstad een land? Heeft elke gebruiker account_details of is het andersom?
Natuurlijk is het voor één-op-veel relaties vrij eenvoudig om de juiste verwijzing in te stellen. Maar toch zijn mensen vaak geneigd om deze relatie om te keren in een array-veld. Denk na over huidige en toekomstige cardinaliteit tussen je modellen en vermijd complexe migraties later.
Maar model X heeft bijna exact dezelfde velden als model Y!
Oh glorieuze overerving! Gij zult polymorfisme niet tevergeefs gebruiken! En gij zult het vooral niet gebruiken als het enige instrument voor hergebruik van code. We zouden elkaar uren van verwarring en refactoring besparen als we zouden stoppen met denken dat DRY het uitbreiden van ouderklassen impliceert.
En dit geldt ook voor database-modellen. Ik heb persoonlijk gevallen gezien waarin database-modellen werden misbruikt zodat een kritische beoordeling van het domeinmodel kon worden vermeden. Stel dat we software voor appartementverhuur bouwen en een apartment_building-model introduceren, is dit niet gewoon een apartment met extra eigenschappen? Misschien een is_building-veld? Je zou de adresmodellen kunnen hergebruiken, het misschien eenvoudig maken om een accountmanagerportfolio te clusteren.
Maar dan probeer je hiërarchie toe te voegen en zelfjoins te doen, spaarzame gebouwspecifieke velden toe te voegen en voor je het weet, vecht je tegen je eigen model.
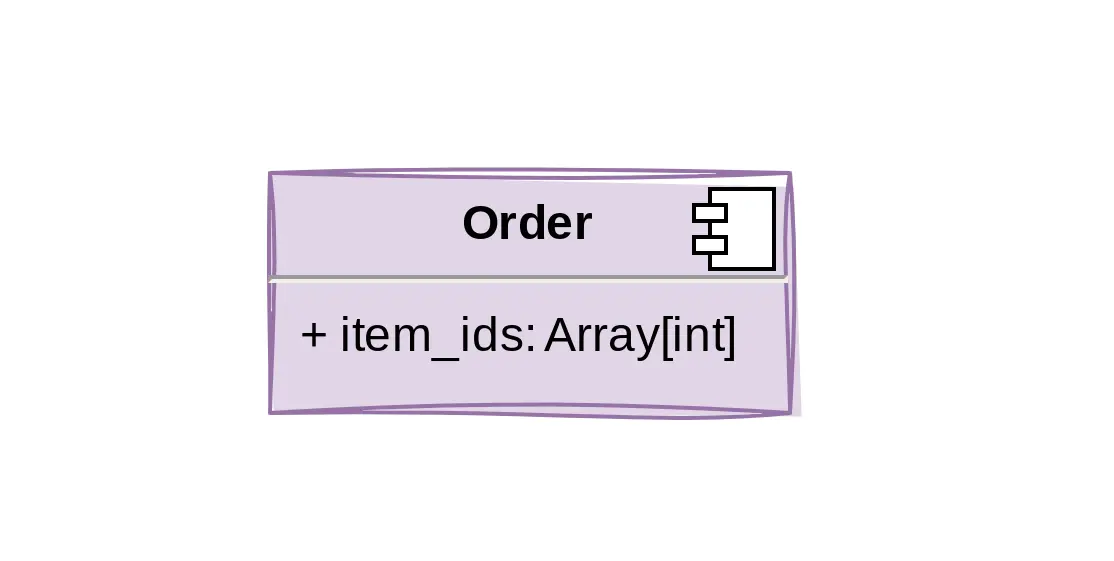
Heeft deze entiteit een reeks gerelateerde waarden? Laten we gewoon een array-veld maken.
We gaan deze waarden toch nooit bevragen.
Zo verleidelijk als het gebrek aan joins klinkt, is er geen veldtype dat waarschijnlijker tot spijt leidt dan het array. Hoewel ze natuurlijk hun nut hebben, moet je je ervan bewust zijn dat het gemakkelijk is om dit te zien als een excuus om many-to-many relaties te vermijden. Hoe weet je of je ze verkeerd gebruikt? Vraag jezelf vele malen af: zal ik ooit filteren op deze waarden? Zullen deze waarden ooit meer informatie vereisen? Moet ik rijen groeperen die een specifieke waarde in hun array bevatten?
Als een van de antwoorden ja is, denk er dan goed over na voordat je dat array-veld toevoegt. Array-velden moeten worden gebruikt wanneer de arrays meestal als geheel worden benaderd en weinig semantische waarde bevatten, niet als shortcut.
Ik weet niet wat dat veld betekent in de context van dit model..
Dus om een Y te maken, moet ik eerst een Q, X en een P maken?
Dit is net zo van toepassing op data-modellering als op algemene OOP. Ik heb schema’s gezien waarin (meerdere) domeinmodellen een veld hebben dat wijst naar de taak die het heeft gegenereerd. Hoewel deze relatie qua cardinaliteit de juiste richting op wijst, kun je snel mogelijke implementatie-uitdagingen met dit model opmerken. Wat als modellen handmatig worden toegevoegd? Wat als nieuwe taken hetzelfde object vinden? Wat als we modellen verwijderen? Beïnvloedt dit de integriteit als we overwegen dat taken met 0 resultaten zijn mislukt?
Je ziet waar dit mis kan gaan. Het herkennen van deze modelleringssignalen komt met ervaring. Het begint met het moeten uitvoeren van dezelfde bewerkingen om je modellen te maken, bij te werken of te bevragen. Het eindigt met niet in staat zijn om functies tijdig te leveren of sommige problemen helemaal niet te kunnen oplossen. Goede data-ingenieurs bouwen functies door nieuwe data-modellen te introduceren. Geweldige data-ingenieurs creëren een model waarin deze functies vanzelfsprekend zijn.
Goede data-ingenieurs bouwen functies door nieuwe data-modellen te introduceren. Geweldige data-ingenieurs creëren een model waarin deze functies vanzelfsprekend zijn.
Ik vond die bruine trui in eerste instantie leuk. (Ik vind veel van mijn ideeën in eerste instantie leuk.) Maar sommige beslissingen hebben de neiging te blijven, vooral de slechte. Mensen bij DoorDash hebben jarenlang gewerkt aan migraties volgens deze presentatie, toepasselijk getiteld “Migraties - Het moeilijkste daadwerkelijke probleem in de informatica”. Het oplossen van de problemen van vandaag is meestal slechts een derde van het probleem.
Geef me een oud project met slechte code maar een solide data-model, en ik zal een plan uitwerken om het te refactoren naar een onderhoudsvriendelijk systeem met minimale impact. Geef me een schoon oud project gebouwd op basis van een slecht data-model, en maak je klaar voor migraties, domeinmodelleringsessies, waarschijnlijk gegevensverlies en het belangrijkste: impact op gebruikers.
Of het nu gaat om kleding of datamodellering, het goed doen kost tijd en moeite. Weeg de trade-offs goed af en probeer indien mogelijk “ontwerp het twee keer” toe te passen. En natuurlijk: let op de tekenen van deze 10 modelleringszonden.

Donny is een wiskundige die als zelfstandig software-/data-ingenieur begon voordat hij BiteStreams mede-oprichtte. Hij kan snel ontwerpfouten herkennen en systemen aanpassen aan zakelijke behoeften. In zijn vrije tijd sport hij graag, leest hij en gaat hij graag iets drinken met vrienden.
Over onsEnjoyed reading this post? Check out our other articles.
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg
 Donny Peeters
Donny Peeters
Wordt meer data gedreven met BiteStreams en laat de concurrentie achter je.
Neem contact met ons op